Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ )
Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para garantizar la disponibilidad.
Si bien las plataformas de virtualización tradicionales manejan esto de forma nativa, ejecutar estas cargas de trabajo en OpenShift bare metal introduce nuevas consideraciones arquitectónicas.
El desafío: ¿Qué sucede cuando falla el sitio principal? ⚠️
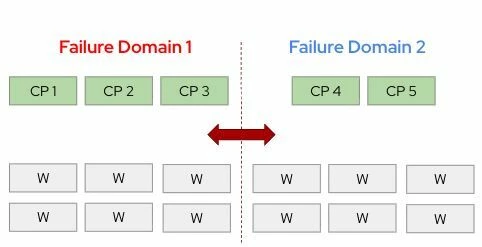
En los clústeres de OpenShift extendidos típicos, el plano de control a menudo se implementa en una topología 2+1 o 1+1+1 .
Pero si el centro de datos que aloja la mayoría de los nodos del plano de control se cae:
- El nodo del plano de control superviviente se convierte en la única fuente de información veraz para el clúster.
- Ese único nodo debe cambiar al modo de lectura y escritura y actuar como la copia exclusiva de etcd.
- Si ese nodo falla… la recuperación se vuelve catastrófica , especialmente al ejecutar máquinas virtuales con estado.
Este riesgo se vuelve aún más crítico en entornos que aprovechan OpenShift Virtualization para cargas de trabajo de producción
La solución: Plano de control de 4 y 5 nodos para clústeres extendidos 🚀
Para aumentar la resiliencia durante fallas a nivel de centro de datos, OpenShift puede aprovechar implementaciones de plano de control de 4 o 5 nodos , como:
- 2+2
- 3+2
Con estos diseños, incluso si se pierde un sitio completo, la ubicación restante conserva dos copias de solo lectura de etcd , lo que aumenta significativamente la capacidad de recuperación del clúster y reduce el riesgo de perder el quórum
Actualmente, el operador cluster-etcd ya admite hasta cinco miembros etcd , con escalado automático en entornos que utilizan MachineSets.
Sin embargo, en instalaciones bare-metal o basadas en agentes , MachineSets no está disponible, lo que significa que el operador no escalará automáticamente, sino que ajustará los pares etcd cuando se agreguen manualmente nodos del plano de control .
Este es exactamente el flujo de trabajo que pretendemos validar y admitir oficialmente.
🔧 Nota: Esta capacidad está específicamente dirigida a clústeres bare-metal , con un fuerte enfoque en los casos de uso de virtualización de OpenShift .
Objetivos 🎯
Validar y admitir arquitecturas de plano de control de 4 y 5 nodos para clústeres bare-metal extendidos, bajo las siguientes restricciones:
- Nodos de plano de control bare-metal
- Instalado mediante el instalador asistido o el instalador basado en agentes
- Red de capa 3 compartida entre ubicaciones
- Latencia < 10 ms entre todos los nodos del plano de control
- Ancho de banda mínimo de 10 Gbps
- etcd almacenado en SSD o NVMe
Criterios de aceptación ✔️
📌 Rendimiento
El rendimiento y la escalabilidad del plano de control deben mostrar una degradación inferior al 10 % en comparación con los clústeres HA estándar.
📌 Procedimientos de recuperación
La documentación debe validarse y actualizarse para la recuperación manual del plano de control en casos de pérdida de quórum.