Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ )
Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para garantizar la disponibilidad. Si bien las plataformas de virtualización tradicionales manejan esto de forma nativa, ejecutar estas cargas de trabajo en OpenShift bare metal introduce nuevas consideraciones arquitectónicas.
El desafío: ¿Qué sucede cuando falla el sitio principal? ⚠️
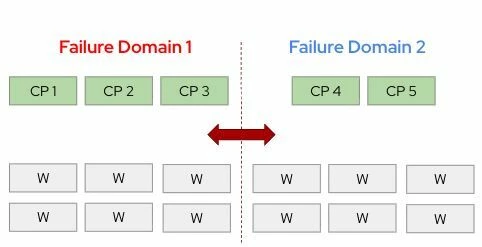
En los clústeres de OpenShift extendidos típicos, el plano de control a menudo se implementa en una topología 2+1 o 1+1+1 . Pero si el centro de datos que aloja la mayoría de los nodos del plano de control se cae:
El nodo del plano de control superviviente se convierte en la única fuente de información veraz para el clúster.
Ese único nodo debe cambiar al modo de lectura y escritura y actuar como la copia exclusiva de etcd.
Si ese nodo falla… la recuperación se vuelve catastrófica , especialmente al ejecutar máquinas virtuales con estado.
Este riesgo se vuelve aún más crítico en entornos que aprovechan OpenShift Virtualization para cargas de trabajo de producción
La solución: Plano de control de 4 y 5 nodos para clústeres extendidos 🚀
Para aumentar la resiliencia durante fallas a nivel de centro de datos, OpenShift puede aprovechar implementaciones de plano de control de 4 o 5 nodos , como:
2+2
3+2
Con estos diseños, incluso si se pierde un sitio completo, la ubicación restante conserva dos copias de solo lectura de etcd , lo que aumenta significativamente la capacidad de recuperación del clúster y reduce el riesgo de perder el quórum
Actualmente, el operador cluster-etcd ya admite hasta cinco miembros etcd , con escalado automático en entornos que utilizan MachineSets. Sin embargo, en instalaciones bare-metal o basadas en agentes , MachineSets no está disponible, lo que significa que el operador no escalará automáticamente, sino que ajustará los pares etcd cuando se agreguen manualmente nodos del plano de control .
Este es exactamente el flujo de trabajo que pretendemos validar y admitir oficialmente.
🔧 Nota: Esta capacidad está específicamente dirigida a clústeres bare-metal , con un fuerte enfoque en los casos de uso de virtualización de OpenShift .
Objetivos 🎯
Validar y admitir arquitecturas de plano de control de 4 y 5 nodos para clústeres bare-metal extendidos, bajo las siguientes restricciones:
Nodos de plano de control bare-metal
Instalado mediante el instalador asistido o el instalador basado en agentes
Red de capa 3 compartida entre ubicaciones
Latencia < 10 ms entre todos los nodos del plano de control
Ancho de banda mínimo de 10 Gbps
etcd almacenado en SSD o NVMe
Criterios de aceptación ✔️
📌 Rendimiento
El rendimiento y la escalabilidad del plano de control deben mostrar una degradación inferior al 10 % en comparación con los clústeres HA estándar.
📌 Procedimientos de recuperación
La documentación debe validarse y actualizarse para la recuperación manual del plano de control en casos de pérdida de quórum.
Todos los que administramos VMware sabemos de lo que hablamos cuando nombramos CPU Ready (%RDY) como Métrica de Rendimiento, entonces explicare que es, y como se mide en Openshift Virtualization.
¿Qué es CPU Ready?
El término “CPU Ready” puede dar lugar a malentendidos. Se podría pensar que representa la cantidad de CPU lista para ser usada y que un alto valor es algo positivo. Sin embargo, cuanto mayor sea el CPU Ready, peor será el rendimiento de la infraestructura vSphere y más sufrirán las aplicaciones.
Definición oficial de VMware:
Es el porcentaje de tiempo en que un «world» está listo para ejecutarse y esperando la aprobación del CPU Scheduler.
En vSphere, un «Ciclo» es un proceso.
Cuanto mayor sea el CPU Ready, más tiempo pasarán las VM sin ejecutar lo que deberían.
En otras palabras, un «Ciclo» es una vCPU esperando su turno para ejecutarse en un CPU físico. CPU Ready mide cuánto tiempo esa vCPU espera para ser programada y ejecutarse en un núcleo físico.
¿Qué causa un alto CPU Ready?
Identificar el alto uso de CPU es sencillo, pero encontrar la causa del CPU Ready puede ser más difícil. Las dos causas principales de un alto CPU Ready son:
Alta sobreasignación de CPU (CPU Oversubscription)
Uso de límites de CPU (CPU Limits)
Sobreasignación de CPU
La razón más común de CPU Ready alto es asignar más vCPUs de las que pueden ser manejadas por los CPU físicos.
Reglas generales para la relación vCPU:pCPU:
1:1 a 1:3 → No hay problema.
1:3 a 1:5 → Puede empezar a degradarse el rendimiento.
1:5 o mayor → Probable problema de CPU Ready.
¿Cómo ver el CPU Ready en VMware?
La mejor manera de analizar CPU Ready es a nivel de VM y por vCPU, no a nivel de host.
En vSphere Client, en los gráficos de rendimiento, se puede agregar CPU Ready como métrica.
En esxtop, se puede ver el %RDY para cada VM.
¿Cuánto CPU Ready es “normal”?
VMware recomienda mantener CPU Ready por debajo del 5% por vCPU.
CPU Ready se mide en milisegundos (ms) en la UI de vSphere, pero para calcular el porcentaje real:
Si en 20 segundos (20000 ms) una VM tiene 2173 ms de CPU Ready, entonces: (2173 / 20000) = 10.87% → Esto es alto.
¿Cómo medir CPU Ready en OpenShift Virtualization?
En VMware vSphere, CPU Ready (%RDY) mide el tiempo que una vCPU pasa esperando ser programada en un CPU físico. En OpenShift Virtualization, no existe una métrica llamada CPU Ready directamente, pero el equivalente en Kubernetes y OpenShift se mide a través del CPU Throttling.
📌 Métrica equivalente en OpenShift:
container_cpu_cfs_throttled_seconds_total
Mide el tiempo total (en segundos) que un contenedor (o VM en OpenShift Virtualization) ha estado «throttled», es decir, ha sido limitado en su uso de CPU porque excedió los recursos asignados.
📌 Otras métricas relacionadas:
container_cpu_cfs_periods_total
Cantidad total de períodos de CPU asignados al contenedor.
container_cpu_cfs_throttled_periods_total
Número de períodos de CPU en los que la VM fue restringida.
Usar Grafana en OpenShift Monitoring
Si tenés configurado Prometheus y Grafana, podés crear un dashboard con:
Métrica:container_cpu_cfs_throttled_seconds_total
Filtro:{pod=~"mi-vm-.*"} (para enfocarse en VMs específicas)
Usar oc adm top para obtener CPU en tiempo real
Comando:oc adm top pods -n mi-namespace
Esto muestra el uso de CPU y memoria en tiempo real para cada VM.
🚀 Recomendaciones para evitar CPU Throttling en OpenShift Virtualization
No usar CPU Limits innecesarios
Si una VM tiene un CPU Limit bajo, puede ser constantemente restringida, causando CPU Throttling alto.
En su lugar, definir solo CPU Requests y dejar el Limit abierto si el host tiene recursos disponibles.
Monitorear y ajustar los recursos asignados
Revisar periódicamente las métricas de CPU Throttling en Prometheus/Grafana.
Asegurar que las VMs críticas tengan suficientes recursos.
Evitar la sobreasignación de vCPUs en los nodos físicos
En OpenShift, asignar más vCPUs de las que tiene el nodo físico puede causar contención y throttling.
Seguir ratios recomendados de vCPU vs. pCPU.
📊 Umbrales para interpretar CPU Throttling en OpenShift
CPU Throttling (%)
Estado
Impacto en el rendimiento
0 – 5%
🔵 Óptimo
No hay impacto en el rendimiento.
5 – 10%
🟡 Advertencia
Posible latencia en aplicaciones sensibles a la CPU.
10 – 20%
🟠 Problema moderado
Pueden aparecer retrasos y degradación en el rendimiento.
> 20%
🔴 Crítico
La VM o contenedor está fuertemente limitado, afectando su desempeño.
🛠️ Comparación rápida: VMware vs. OpenShift Virtualization
Capítulo 1, «Hardware para Uso con VMware vSphere», en la página 11, ofrece orientación sobre la selección de hardware para usar con vSphere.
Capítulo 2, «ESXi y Máquinas Virtuales», en la página 25, proporciona orientación sobre el software VMware ESXi™ y las máquinas virtuales que se ejecutan en él.
Capítulo 3, «Sistemas Operativos Huésped», en la página 55, brinda orientación sobre los sistemas operativos huésped que se ejecutan en las máquinas virtuales de vSphere.
Capítulo 4, «Gestión de Infraestructura Virtual», en la página 67, ofrece orientación sobre las mejores prácticas de gestión de infraestructura.
Audiencia Prevista: Este libro está dirigido a administradores de sistemas que estén planificando una implementación de VMware vSphere 8.0 Actualización 2 y deseen maximizar su rendimiento. El libro asume que el lector ya está familiarizado con los conceptos y la terminología de VMware vSphere.
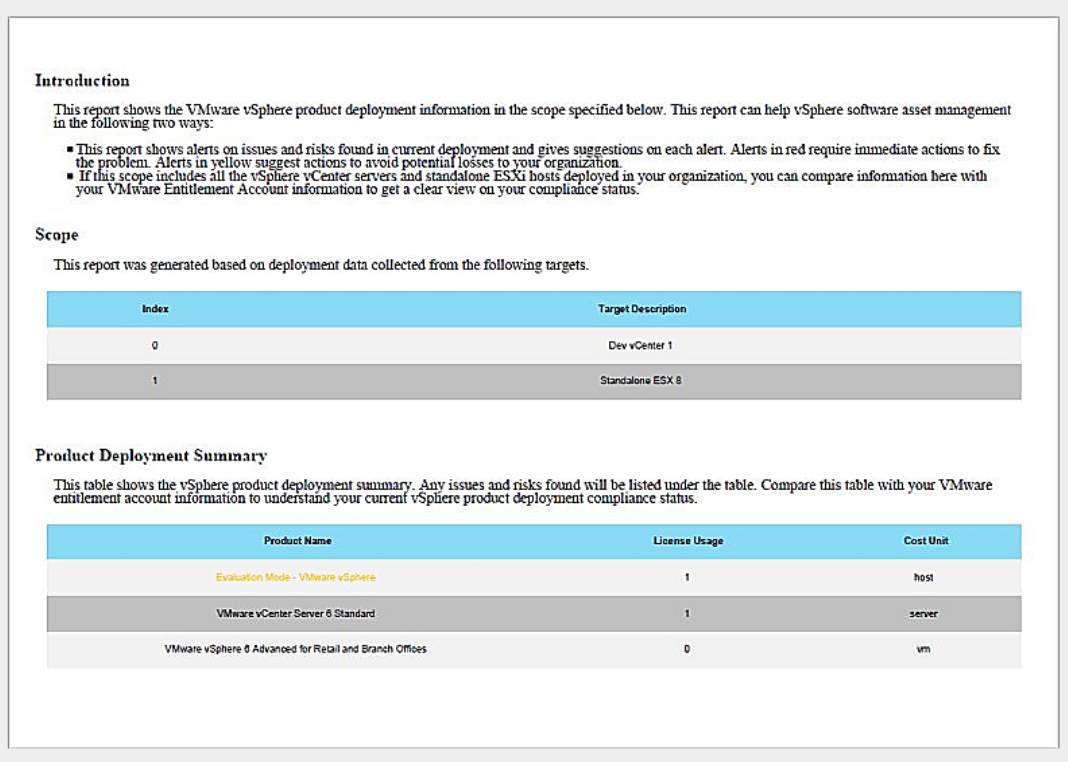
Hola !! les traigo una herramienta super util para todos, vSAM recopila y resume la información de implementación de productos vSphere. Requiere las API de vSphere para los datos de implementación y produce un informe en PDF que el cliente puede consultar como parte de su proceso de revisión y planificación de la infraestructura
Gestionar la configuración entre vCenters desde una consola de gestión central accesible desde cualquier lugar es ahora una realidad.
Servicios de desarrollo:
Transformarías tu infraestructura virtual en una plataforma lista para desarrolladores con VMware Tanzu
VMware Tanzu Runtime y Tanzu Mission Control Essentials formarán parte de vSphere+ sin cargo adicional.
Servicios adicionales en la nube:
Una vez conectados a VMware Cloud, los clientes pueden utilizar servicios basados en la nube como VMware Cloud Disaster Recovery (VCDR) en un enfoque sin problemas y estrechamente integrado.
Muévete fácilmente a un modelo de consumo de OpEx convirtiendo licencias perpetuas desde la VMware Console. Una vez pasado al modelo de suscripción, los clientes pueden implementar un número ilimitado de vCenters en las instalaciones sin costo adicional como mencionamos anteriormente.
Paso 1 – Crear una cuenta y organización de VMware Cloud
Los clientes se pondrán en contacto con su representante de VMware para planificar y determinar la licencia requerida. Los clientes existentes pueden actualizar/convertir su inversión actual en suscripción a través del Programa de Actualización de Suscripción (SUP). Una vez que se haya completado la adquisición/conversión de la licencia, se notificará a los clientes la preparación de los derechos, y en este punto el cliente creará una cuenta de VMware Cloud (si aún no se ha creado) y una organización dentro de los servicios en la nube de VMware
Paso 2 – Implementar el dispositivo Cloud Gateway
El paso 2 implica descargar e instalar un dispositivo Cloud Gateway en el vCenter local que se va a añadir. Este dispositivo se puede descargar desde nuestro sitio web y se implementará en un clúster de vSphere existente. El dispositivo se utiliza como Bridge de comunicación entre vCenter(s) y la Nube. No hay conexión directa desde vCenter a la Nube, y toda la comunicación desde el dispositivo Cloud Gateway a la nube está cifrada. No se transmiten nombres de usuario ni contraseñas externamente.
Paso 3 – Conecte su nube privada a VMware Cloud Services
Hasta este punto, hemos creado una cuenta y una organización de VMware Cloud, e implementado el dispositivo Cloud Gateway. Este siguiente paso es simplemente conectar su dispositivo Cloud Gateway a la cuenta de VMware Cloud y seleccionar una organización que tenga derechos de vSphere+. En este paso, esencialmente estamos emparejando el Gateway con la organización de la nube.
Paso 4 – Registre sus instancias de vCenter Server
Este último paso también es muy simple, aquí registraremos el (los) vCenter(s) en el Cloud Gateway Appliance. Recuerde que el Gateway ya sabe dónde conectarse. Cuando registramos uno o más vCenters en el Gateway, la conexión a la nube se completa y, en pocos minutos, los clientes pueden comenzar a disfrutar de los beneficios de una infraestructura local conectada a la nube. El resultado es una consola en la nube para gestionar todos los entornos locales
En este Link podremos acceder al Veeam Size Estimator, una herramienta extremadamente útil para estimar el tamaño de tus datos respaldados. Podrás determinar cuánto espacio de almacenamiento necesitarás para tus copias de seguridad y así planificar adecuadamente los recursos requeridos.
El Veeam Size Estimator te permite ingresar diferentes parámetros, como la cantidad de máquinas virtuales, el tamaño de los discos, el nivel de cambio diario y la retención deseada, entre otros. A partir de estos datos, la herramienta realiza cálculos complejos y te proporciona un estimado detallado sobre el espacio de almacenamiento necesario y el crecimiento esperado en el tiempo. Esto es especialmente útil para empresas de todos lostamaños que desean garantizar que su infraestructura de respaldo cumpla con los requisitos de capacidad y rendimiento.
Además de ayudarte a planificar los recursos necesarios, el Veeam Size Estimator también te permite explorar diferentes configuraciones y escenarios. Puedes ajustar los parámetros y ver cómo varía el tamaño estimado del respaldo. Esto te brinda flexibilidad para adaptar tu infraestructura de respaldo a medida que cambian las necesidades de tu organización.
No dudes en aprovechar esta herramienta y estar un paso adelante en la protección de tus datos críticos.
👉 Empecemos 🤓 Paso 1
Podemos ir añadiendo algunos sitios. Un sitio actúa como un mecanismo de grupo para recursos como repositorios y cargas de trabajo. Se supone que los recursos del sitio están bien conectados. Por lo general, un sitio es un centro de datos o una ubicación física. Por ejemplo, en un entorno de producción, es posible que tengas un centro de datos en Peru y Argentina. En este caso, puede crear un sitio para representar cada ubicación, una llamada Londres y la otra. Puede optar por generar automáticamente un repositorio predeterminado en cada sitio para crear una copia de seguridad local. De forma predeterminada, el asistente crea 2 sitios que representan un diseño simple de dos centros de datos. Si estás satisfecho con este diseño simple, no tienes que cambiar nada y puedes seguir con el siguiente paso.
👉 Paso 2
Los repositorios pueden representar un repositorio de copia de seguridad único o un repositorio de Scale-Out. Como esta en la imagen hemos creado 1 repositorio por sitio que permite una copia fuera del sitio.
Opcionalmente, puede configurar los datos de copia de seguridad por niveles en la nube (Object Storage) en este paso, de la manera que lo haría en VBR.
Consejo: También puede crear 2 (o más) repositorios por sitio, uno para copias de seguridad locales y otro para recibir los trabajos de copia de seguridad. Esto le permite ver la diferencia entre las copias de seguridad locales y las copias entrantes
👉 Paso 3
Los perfiles son preajustes que puedes reutilizar en las pestañas de carga de trabajo. El perfil o preajuste más relevante es el perfil de retención, que le permite definir su retención para sus copias de seguridad. Al definirlo por separado, puede (re)utilizarlos al definir sus cargas de trabajo y adaptarlos rápidamente para simular diferentes SLA.
Consejo: Establezca su perfil principal como el perfil predeterminado en cualquiera de las pestañas. Cuando creas una nueva carga de trabajo, el ajuste preestablecido predeterminado se seleccionará automáticamente.
Hay 4 tipos principales
Retención: define el SLA, por lo general cargas de trabajo similares comparten el mismo SLA. Por lo general, esta es la cantidad de incrementales (diarios) + los Fulls de GFS que quieres mantener. Consulte la documentación de Veeam Backup & Replication
Ventanas de copia de seguridad: definen el tiempo máximo que el sistema puede ocupar para hacer una copia de seguridad de una determinada carga de trabajo. Esto tiene un impacto en el tamaño de la CPU y la memoria. Si la ventana de copia de seguridad es más pequeña para las mismas cargas de trabajo, el sistema debe hacer una copia de seguridad de más cargas de trabajo en paralelo. Una ventana de copia de seguridad tiene 2 ajustes, incrementales y completos. Incremental es el tiempo que se suele utilizar para ejecutar una copia de seguridad. La ventana de copia de seguridad completa es la cantidad de tiempo que el sistema puede tardar en hacer una copia de seguridad completa. Por lo general, ejecutar una copia de seguridad completa es una rara opción o se puede extender a lo largo de varios días con múltiples trabajos. Es por eso que, por lo general, estas ventanas son más grandes, ya que es poco común hacer una copia de seguridad de toda la carga de trabajo a la vez, excepto al principio
Propiedades de los datos: define cómo se comportan los datos a lo largo del tiempo. Por ejemplo, describe la tasa de cambio diario o el crecimiento anual. Las propiedades de los datos suelen compartirse entre cargas de trabajo similares.
General: Ajustes generales que se aplican en todo el tamaño, independientemente de las cargas de trabajo individuales.
👉 Paso 4
El VSE se centra en las cargas de trabajo. Las cargas de trabajo representan máquinas virtuales, máquinas físicas de Windows u otros conjuntos de datos que requieren una copia de seguridad. Las cargas de trabajo son un mecanismo para agrupar ciertos tipos de conjuntos de datos. Por ejemplo, 3 máquinas virtuales SQL de cada 1 TB de tamaño requieren estar protegidas con un SLA similar. En este caso, se puede crear una sola carga de trabajo «VM SQL» de tipo VM con un tamaño de fuente de 3 TB e instancias o unidades establecidas en 3 (represeniendo 3 máquinas virtuales). De manera similar, si tiene 4 máquinas físicas Linux, puede crear una carga de trabajo y establecer el tamaño de la fuente en la suma de todos los datos actualmente consumidos en el disco en estas máquinas físicas. En este caso, establezca la carga de trabajo en el tipo «Agente»
Las cargas de trabajo se ejecutan en servidores físicos directamente (copia de seguridad basada en agentes) o virtualmente en un hipervisor. Estas máquinas físicas se encuentran en una ubicación física a menudo conocida como centro de datos o sitio. Los sitios le permiten presentar esta ubicación física y asignarles las cargas de trabajo para que la herramienta de tamaño sepa dónde se encuentran. Le permiten agrupar las cargas de trabajo y los repositorios que documentan el diseño actual de un entorno de producción.
Los repositorios son repositorios de Veeam Backup & Replication en los que puede hacer una copia de seguridad de los datos de sus cargas de trabajo. Representan activos de infraestructuras físicas como un servidor x64, dispositivos NAS, etc. Están ubicados dentro de un sitio. Por lo general, las cargas de trabajo se respaldan en un repositorio local (en el mismo sitio) y se copian en un repositorio externo. Se puede configurar la copia entre sitios.
En caso de que esté utilizando el almacenamiento de objetos como destino local, puede considerar el tamaño de bloque de 4 MB si su proveedor de almacenamiento de objetos lo recomienda. El tamaño del bloque de 4 MB limita la cantidad de factor de metadatos por un factor potencial de 4 en comparación con el tamaño de bloque tradicional de 1 MB. Esto puede mejorar las operaciones de manejo de meta, como las eliminaciones o el bloqueo de objetos, ya que se crean menos bloques. Considere un disco de 100 GB. Con un tamaño de bloque de 1 MB, obtienes un total de 100.000 bloques durante una copia de seguridad completa. Sin embargo, con un tamaño de bloque de 4 MB, este número se reduce a 25.000 bloques.
Sin embargo, esto se produce con un mayor consumo de almacenamiento en un factor potencial de 4 durante la copia de seguridad incremental. Sin embargo, según la experiencia de campo, este factor es más probable que sea 2x. Esto se debe a que los sistemas de archivos modernos intentan mantener juntos los bloques de datos para el mismo archivo de una manera secuencial que mitiga el impacto de un tamaño de bloque más grande.
Por último, múltiples cargas de trabajo podrían compartir características similares. Es por eso que se abstraen en los perfiles. Esto elimina las necesidades de redefinirlos una y otra vez. El perfil predeterminado se seleccionará cuando agregue una carga de trabajo, por lo que es una buena idea establecerlo como predeterminado cuando haya un perfil que cubra la mayoría de las cargas de trabajo.
👉 Paso 5 Resultados 🏁
Aqui vemos como resultado los Cores y la Memoria RAM que necesitaran los componentes de Veeam para el entorno que hemos propuesto & la capacidad de Storage del mismo.
Espero que les haya servido !!!
Aqui Tambien les dejo como realizar estos calculos manualmente
Puede inscribir dispositivos que ejecuten cualquier distribución de Linux que se ejecute en arquitecturas x86_64, ARM5 o ARM7 en Workspace ONE UEM.
Los instaladores se crean para distribuciones y arquitecturas específicas. Asegúrese de que está utilizando el instalador correcto para su caso de uso.
El dispositivo debe estar ejecutando System D o System V para que Hub se ejecute como un servicio del sistema.
The Puppet agent (código abierto) es necesario para las configuraciones que utilizan perfiles de Workspace ONE. Si ejecuta un sistema basado en Debian (deb) o Red Hat (rpm), esto se instalará automáticamente con Hub. Para otros sistemas, o cuando se utiliza el método de instalación tarball, debe instalarse manualmente antes de la inscripción en WS1.
Requisitos de Workspace ONE UEM
No esta disponible para entornos On-Prem, Workspace ONE UEM se ha sometido a una rearquitectura completa. Actualmente, esto está disponible en entornos Saas UAT compartidos CN135, CN137 y CN138 y lo implementaremos en entornos Saas dedicados y compartidos después de que se implementen el nuevo Control Plane y UEM v2109
La forma más fácil de validar si la gestión de Linux está habilitada o no en su entorno Workspace ONE UEM es crear un nuevo perfil y comprobar si Linux es una plataforma disponible. Para ello, vaya a Recursos > Perfiles y líneas base > Perfiles > Añadir > Añadir perfil.
Si ve Linux como una plataforma disponible, similar a la siguiente captura de pantalla, su entorno SaaS se ha actualizado y puede inscribir un dispositivo Linux.
Que se podrá hacer con Linux en WS1
Sampling Support en Linux
Soporte para perfiles de Wi-Fi y credenciales
Gestión del ciclo de vida del certificado de soporte
Sensores Workspace ONE para Linux
Configuración del dispositivo que utiliza código abierto de Puppet (perfil de configuración personalizado)
Mejoras de configuración personalizadas (opciones para hacer cumplir y eliminar manifiestos)
Admite gestión remota (WS1 Assist) para dispositivos Linux
Mejore y mejore la interfaz de línea de comandos del Hub
📌 Recordemos que iran liberando muchisimas capacidades en cada realease de WS1
Inscribir sus dispositivos Linux
Descargue Workspace ONE Intelligent Hub para Linux en su dispositivo previsto. El archivo descargado debe corresponder a la arquitectura y distribución del procesador objetivo. El agente está disponible como paquetes deb, rpm o tgz y se puede descargar directamente en su dispositivo Linux o se puede transferir al dispositivo Linux a través de USB o SSH.
Los instaladores se pueden recuperar de las siguientes ubicaciones:
2. Ejecute el instalador del cliente Workspace ONE Intelligent Hub con privilegios de root.
Por ejemplo:
Para el paquete Debian en Ubuntu: $ sudo apt install «/tmp/workspaceone-intelligent-hub-amd64-21.10.0.1.deb»
Para el paquete de RPM en Fedora: $ sudo dnf install workspaceone-intelligent-hub-amd64-21.10.0.1.rpm
Para el paquete RPM en OpenSUSE: $ sudo zypper install workspaceone-intelligent-hub-amd64-21.10.0.1.rpm
Para Tarball (cualquier otra distribución de Linux): 1. Extraiga el paquete usando: $ tar xvf workspaceone-intelligent-hub-<arch>.21.10.0.1.tgz 2. Instale el paquete usando: $ sudo ./install.sh
Nota: Al utilizar Tarball, Ruby debe instalarse manualmente antes de instalar el Intelligent Hub.
3. InscripciónInscriba su dispositivo en Workspace ONE UEM después de la instalación utilizando thews1HubUtil. Elija enviar los detalles de inscripción en un solo comando o por separado. Siga los pasos a continuación para enviarlos en un solo comando.
4. Cambie el directorio al directorio binario Hub bajo el directorio de instalación.
Para solicitar a los usuarios las credenciales de inscripción cuando se inscriban, ejecute ws1HubUtil sin estos argumentos adicionales. Consulte Argumentos de línea de comandos admitidos para obtener más detalles antes de intentar una inscripción.
6. Después de una instalación y registro exitosos, el dispositivo Linux aparecerá en la consola WS1 UEM.
7. Desinstalar:
Para desinstalar Intelligent Hub para Linux, puede enviar un comando Enterprise Wipe desde la consola WS1 UEM (para un dispositivo inscrito) o puede desinstalar manualmente el lado del dispositivo. Si el comando de desinstalación se utiliza en el lado del dispositivo inscrito, el dispositivo se cancelará primero.
Para Debian: $ sudo apt eliminar workspaceone-intelligent-hub
Para RPM para Fedora: $ sudo zypper eliminar espacio de trabajoone-intelligent-hub
Para Tarball: $ sudo /opt/Workspace-ONE-Intelligent-Hub/uninstall.sh
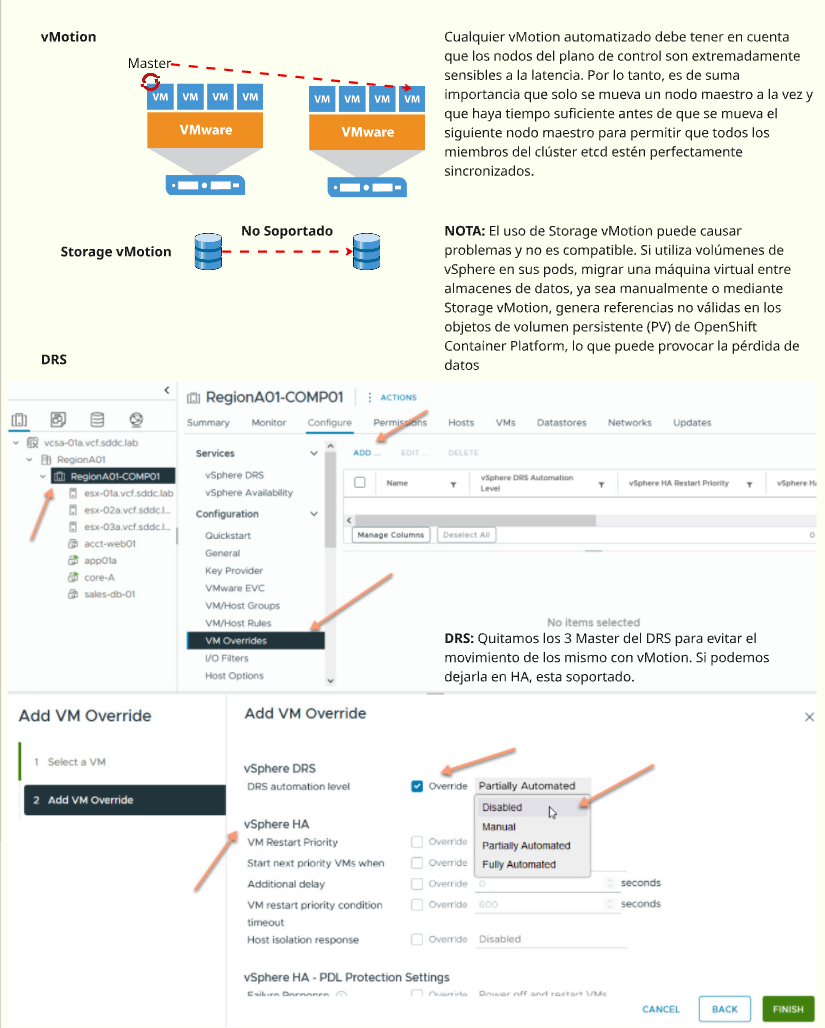
Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ ) Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para…
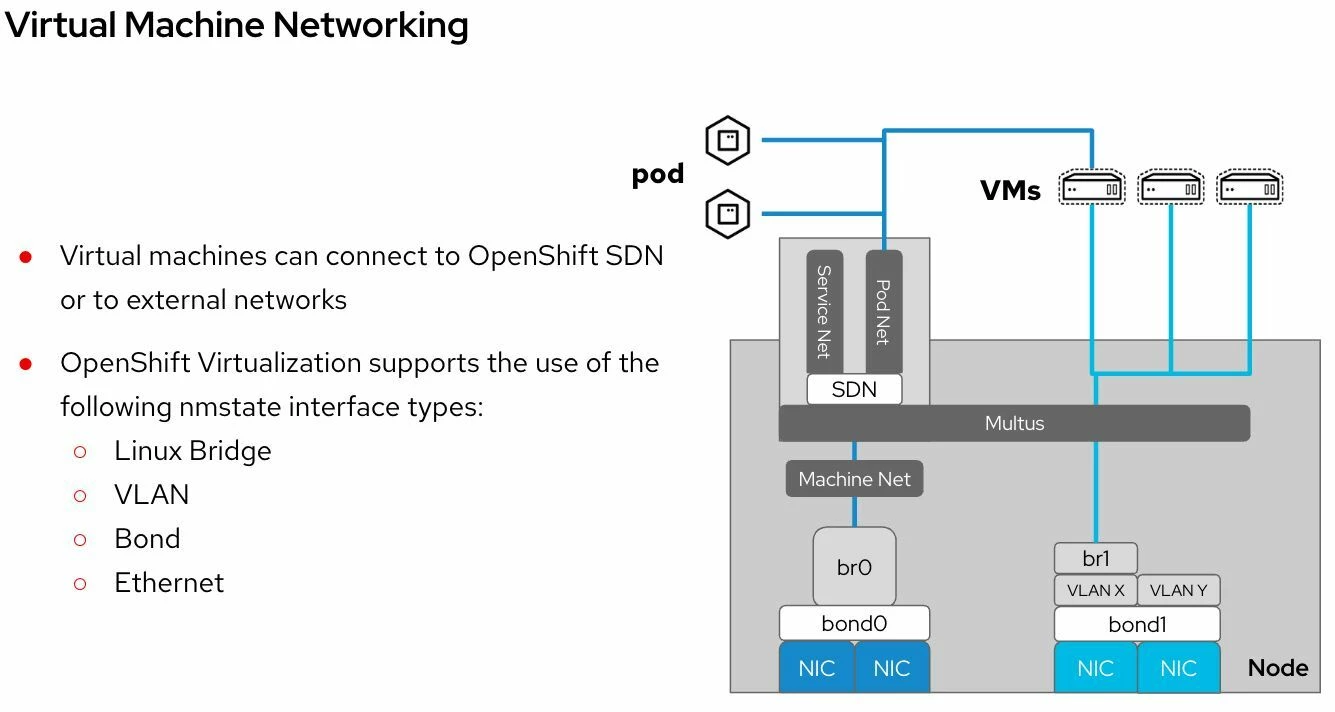
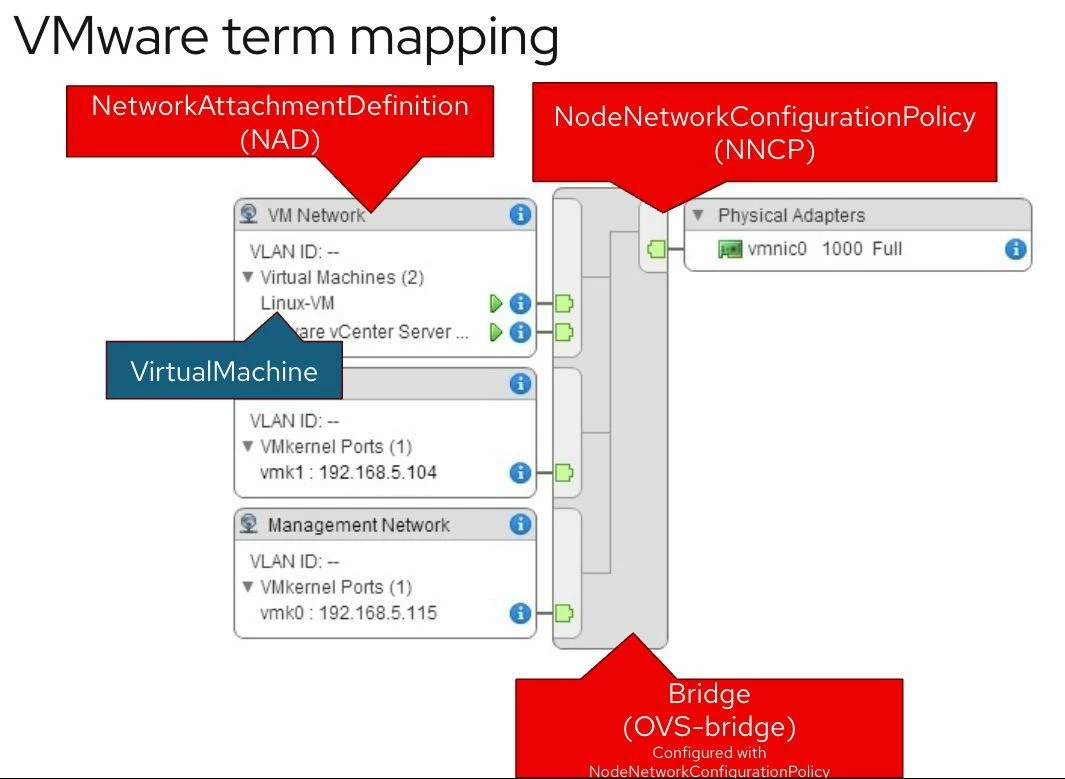
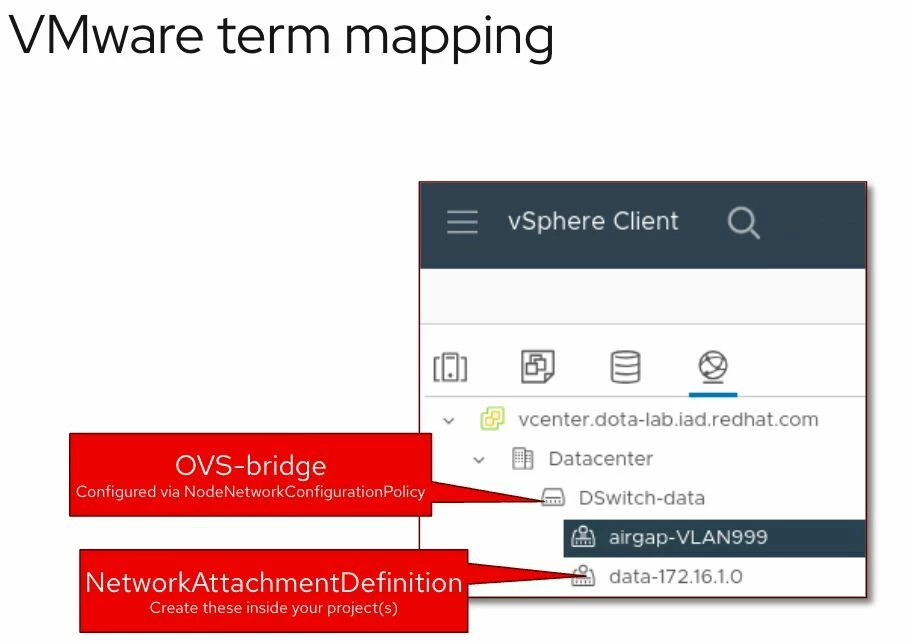
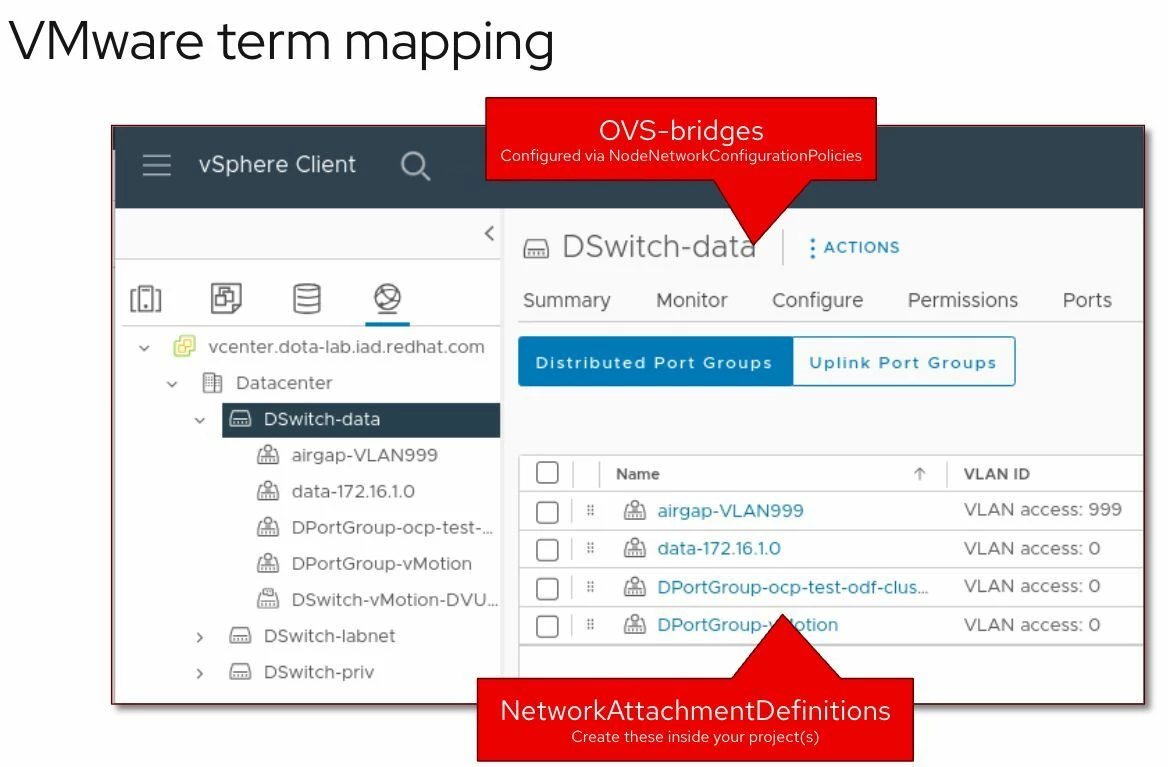
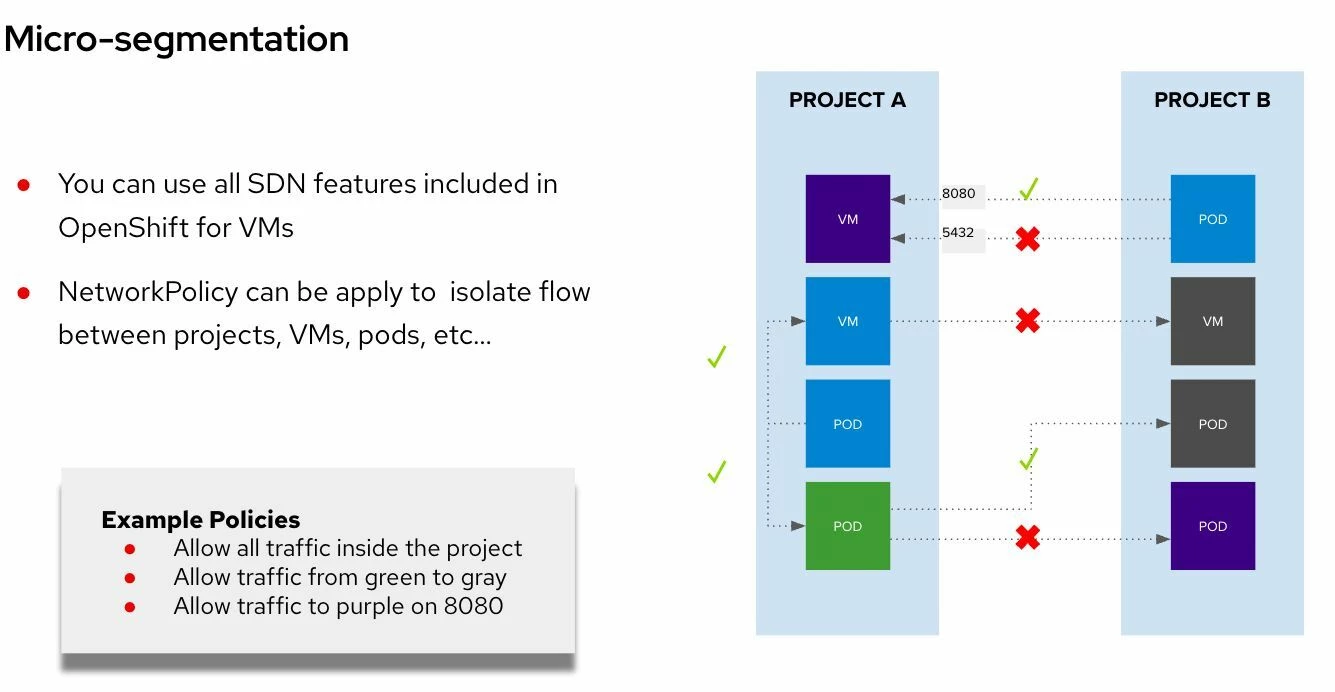
Todo lo mostrado aquí está incluido en todas las suscripciones de OpenShift. Al migrar desde VMware, una de las primeras dudas es cómo se trasladan los conceptos de red. Este post lo explica visualmente. Figure 1: Virtual Machine Networking in OpenShift Las VMs pueden conectarse a: Interfaces soportadas: Esto permite emular redes como las de VMware…
📌 Sesión VI1553: Obtén una comprensión más profunda de #DeFi 💰 y cómo funciona un #DEX 💳 . Nos sumergiremos en los detalles técnicos y demostraremos una #dApp 💯 de intercambio de #tokens construida sobre #VMBC.
📌 Sesión 1553: Aprende a crear un intercambio de activos digitales #NFT usando #VMBC.
📌 Sesión APP1781: Obtén una visión del futuro de #DevSecOps con Web3 Distributed Ledger Technologies
Todos los que administramos VMware sabemos de lo que hablamos cuando nombramos CPU Ready (%RDY) como Métrica de Rendimiento, entonces explicare que es, y como se mide en Openshift Virtualization. ¿Qué es CPU Ready? El término “CPU Ready” puede dar lugar a malentendidos. Se podría pensar que representa la cantidad de CPU lista para ser…
Buenas a todos, les dejo por aqui el 🎁 de este super Book que nos trae todas las buenas practicas de Performance en vSphere 8.0 U2. Download Aquí Book Este libro consta de los siguientes capítulos: Audiencia Prevista: Este libro está dirigido a administradores de sistemas que estén planificando una implementación de VMware vSphere 8.0 Actualización 2 y…
Hola !! les traigo una herramienta super util para todos, vSAM recopila y resume la información de implementación de productos vSphere. Requiere las API de vSphere para los datos de implementación y produce un informe en PDF que el cliente puede consultar como parte de su proceso de revisión y planificación de la infraestructura Podes…