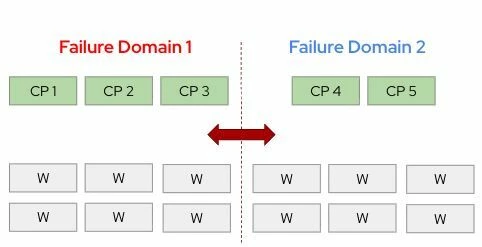
Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ )
Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para garantizar la disponibilidad. Si bien las plataformas de virtualización tradicionales manejan esto de forma nativa, ejecutar estas cargas de trabajo en OpenShift bare metal introduce nuevas consideraciones arquitectónicas.
El desafío: ¿Qué sucede cuando falla el sitio principal? ⚠️
En los clústeres de OpenShift extendidos típicos, el plano de control a menudo se implementa en una topología 2+1 o 1+1+1 . Pero si el centro de datos que aloja la mayoría de los nodos del plano de control se cae:
El nodo del plano de control superviviente se convierte en la única fuente de información veraz para el clúster.
Ese único nodo debe cambiar al modo de lectura y escritura y actuar como la copia exclusiva de etcd.
Si ese nodo falla… la recuperación se vuelve catastrófica , especialmente al ejecutar máquinas virtuales con estado.
Este riesgo se vuelve aún más crítico en entornos que aprovechan OpenShift Virtualization para cargas de trabajo de producción
La solución: Plano de control de 4 y 5 nodos para clústeres extendidos 🚀
Para aumentar la resiliencia durante fallas a nivel de centro de datos, OpenShift puede aprovechar implementaciones de plano de control de 4 o 5 nodos , como:
2+2
3+2
Con estos diseños, incluso si se pierde un sitio completo, la ubicación restante conserva dos copias de solo lectura de etcd , lo que aumenta significativamente la capacidad de recuperación del clúster y reduce el riesgo de perder el quórum
Actualmente, el operador cluster-etcd ya admite hasta cinco miembros etcd , con escalado automático en entornos que utilizan MachineSets. Sin embargo, en instalaciones bare-metal o basadas en agentes , MachineSets no está disponible, lo que significa que el operador no escalará automáticamente, sino que ajustará los pares etcd cuando se agreguen manualmente nodos del plano de control .
Este es exactamente el flujo de trabajo que pretendemos validar y admitir oficialmente.
🔧 Nota: Esta capacidad está específicamente dirigida a clústeres bare-metal , con un fuerte enfoque en los casos de uso de virtualización de OpenShift .
Objetivos 🎯
Validar y admitir arquitecturas de plano de control de 4 y 5 nodos para clústeres bare-metal extendidos, bajo las siguientes restricciones:
Nodos de plano de control bare-metal
Instalado mediante el instalador asistido o el instalador basado en agentes
Red de capa 3 compartida entre ubicaciones
Latencia < 10 ms entre todos los nodos del plano de control
Ancho de banda mínimo de 10 Gbps
etcd almacenado en SSD o NVMe
Criterios de aceptación ✔️
📌 Rendimiento
El rendimiento y la escalabilidad del plano de control deben mostrar una degradación inferior al 10 % en comparación con los clústeres HA estándar.
📌 Procedimientos de recuperación
La documentación debe validarse y actualizarse para la recuperación manual del plano de control en casos de pérdida de quórum.
En este Link podremos acceder al Veeam Size Estimator, una herramienta extremadamente útil para estimar el tamaño de tus datos respaldados. Podrás determinar cuánto espacio de almacenamiento necesitarás para tus copias de seguridad y así planificar adecuadamente los recursos requeridos.
El Veeam Size Estimator te permite ingresar diferentes parámetros, como la cantidad de máquinas virtuales, el tamaño de los discos, el nivel de cambio diario y la retención deseada, entre otros. A partir de estos datos, la herramienta realiza cálculos complejos y te proporciona un estimado detallado sobre el espacio de almacenamiento necesario y el crecimiento esperado en el tiempo. Esto es especialmente útil para empresas de todos lostamaños que desean garantizar que su infraestructura de respaldo cumpla con los requisitos de capacidad y rendimiento.
Además de ayudarte a planificar los recursos necesarios, el Veeam Size Estimator también te permite explorar diferentes configuraciones y escenarios. Puedes ajustar los parámetros y ver cómo varía el tamaño estimado del respaldo. Esto te brinda flexibilidad para adaptar tu infraestructura de respaldo a medida que cambian las necesidades de tu organización.
No dudes en aprovechar esta herramienta y estar un paso adelante en la protección de tus datos críticos.
👉 Empecemos 🤓 Paso 1
Podemos ir añadiendo algunos sitios. Un sitio actúa como un mecanismo de grupo para recursos como repositorios y cargas de trabajo. Se supone que los recursos del sitio están bien conectados. Por lo general, un sitio es un centro de datos o una ubicación física. Por ejemplo, en un entorno de producción, es posible que tengas un centro de datos en Peru y Argentina. En este caso, puede crear un sitio para representar cada ubicación, una llamada Londres y la otra. Puede optar por generar automáticamente un repositorio predeterminado en cada sitio para crear una copia de seguridad local. De forma predeterminada, el asistente crea 2 sitios que representan un diseño simple de dos centros de datos. Si estás satisfecho con este diseño simple, no tienes que cambiar nada y puedes seguir con el siguiente paso.
👉 Paso 2
Los repositorios pueden representar un repositorio de copia de seguridad único o un repositorio de Scale-Out. Como esta en la imagen hemos creado 1 repositorio por sitio que permite una copia fuera del sitio.
Opcionalmente, puede configurar los datos de copia de seguridad por niveles en la nube (Object Storage) en este paso, de la manera que lo haría en VBR.
Consejo: También puede crear 2 (o más) repositorios por sitio, uno para copias de seguridad locales y otro para recibir los trabajos de copia de seguridad. Esto le permite ver la diferencia entre las copias de seguridad locales y las copias entrantes
👉 Paso 3
Los perfiles son preajustes que puedes reutilizar en las pestañas de carga de trabajo. El perfil o preajuste más relevante es el perfil de retención, que le permite definir su retención para sus copias de seguridad. Al definirlo por separado, puede (re)utilizarlos al definir sus cargas de trabajo y adaptarlos rápidamente para simular diferentes SLA.
Consejo: Establezca su perfil principal como el perfil predeterminado en cualquiera de las pestañas. Cuando creas una nueva carga de trabajo, el ajuste preestablecido predeterminado se seleccionará automáticamente.
Hay 4 tipos principales
Retención: define el SLA, por lo general cargas de trabajo similares comparten el mismo SLA. Por lo general, esta es la cantidad de incrementales (diarios) + los Fulls de GFS que quieres mantener. Consulte la documentación de Veeam Backup & Replication
Ventanas de copia de seguridad: definen el tiempo máximo que el sistema puede ocupar para hacer una copia de seguridad de una determinada carga de trabajo. Esto tiene un impacto en el tamaño de la CPU y la memoria. Si la ventana de copia de seguridad es más pequeña para las mismas cargas de trabajo, el sistema debe hacer una copia de seguridad de más cargas de trabajo en paralelo. Una ventana de copia de seguridad tiene 2 ajustes, incrementales y completos. Incremental es el tiempo que se suele utilizar para ejecutar una copia de seguridad. La ventana de copia de seguridad completa es la cantidad de tiempo que el sistema puede tardar en hacer una copia de seguridad completa. Por lo general, ejecutar una copia de seguridad completa es una rara opción o se puede extender a lo largo de varios días con múltiples trabajos. Es por eso que, por lo general, estas ventanas son más grandes, ya que es poco común hacer una copia de seguridad de toda la carga de trabajo a la vez, excepto al principio
Propiedades de los datos: define cómo se comportan los datos a lo largo del tiempo. Por ejemplo, describe la tasa de cambio diario o el crecimiento anual. Las propiedades de los datos suelen compartirse entre cargas de trabajo similares.
General: Ajustes generales que se aplican en todo el tamaño, independientemente de las cargas de trabajo individuales.
👉 Paso 4
El VSE se centra en las cargas de trabajo. Las cargas de trabajo representan máquinas virtuales, máquinas físicas de Windows u otros conjuntos de datos que requieren una copia de seguridad. Las cargas de trabajo son un mecanismo para agrupar ciertos tipos de conjuntos de datos. Por ejemplo, 3 máquinas virtuales SQL de cada 1 TB de tamaño requieren estar protegidas con un SLA similar. En este caso, se puede crear una sola carga de trabajo «VM SQL» de tipo VM con un tamaño de fuente de 3 TB e instancias o unidades establecidas en 3 (represeniendo 3 máquinas virtuales). De manera similar, si tiene 4 máquinas físicas Linux, puede crear una carga de trabajo y establecer el tamaño de la fuente en la suma de todos los datos actualmente consumidos en el disco en estas máquinas físicas. En este caso, establezca la carga de trabajo en el tipo «Agente»
Las cargas de trabajo se ejecutan en servidores físicos directamente (copia de seguridad basada en agentes) o virtualmente en un hipervisor. Estas máquinas físicas se encuentran en una ubicación física a menudo conocida como centro de datos o sitio. Los sitios le permiten presentar esta ubicación física y asignarles las cargas de trabajo para que la herramienta de tamaño sepa dónde se encuentran. Le permiten agrupar las cargas de trabajo y los repositorios que documentan el diseño actual de un entorno de producción.
Los repositorios son repositorios de Veeam Backup & Replication en los que puede hacer una copia de seguridad de los datos de sus cargas de trabajo. Representan activos de infraestructuras físicas como un servidor x64, dispositivos NAS, etc. Están ubicados dentro de un sitio. Por lo general, las cargas de trabajo se respaldan en un repositorio local (en el mismo sitio) y se copian en un repositorio externo. Se puede configurar la copia entre sitios.
En caso de que esté utilizando el almacenamiento de objetos como destino local, puede considerar el tamaño de bloque de 4 MB si su proveedor de almacenamiento de objetos lo recomienda. El tamaño del bloque de 4 MB limita la cantidad de factor de metadatos por un factor potencial de 4 en comparación con el tamaño de bloque tradicional de 1 MB. Esto puede mejorar las operaciones de manejo de meta, como las eliminaciones o el bloqueo de objetos, ya que se crean menos bloques. Considere un disco de 100 GB. Con un tamaño de bloque de 1 MB, obtienes un total de 100.000 bloques durante una copia de seguridad completa. Sin embargo, con un tamaño de bloque de 4 MB, este número se reduce a 25.000 bloques.
Sin embargo, esto se produce con un mayor consumo de almacenamiento en un factor potencial de 4 durante la copia de seguridad incremental. Sin embargo, según la experiencia de campo, este factor es más probable que sea 2x. Esto se debe a que los sistemas de archivos modernos intentan mantener juntos los bloques de datos para el mismo archivo de una manera secuencial que mitiga el impacto de un tamaño de bloque más grande.
Por último, múltiples cargas de trabajo podrían compartir características similares. Es por eso que se abstraen en los perfiles. Esto elimina las necesidades de redefinirlos una y otra vez. El perfil predeterminado se seleccionará cuando agregue una carga de trabajo, por lo que es una buena idea establecerlo como predeterminado cuando haya un perfil que cubra la mayoría de las cargas de trabajo.
👉 Paso 5 Resultados 🏁
Aqui vemos como resultado los Cores y la Memoria RAM que necesitaran los componentes de Veeam para el entorno que hemos propuesto & la capacidad de Storage del mismo.
Espero que les haya servido !!!
Aqui Tambien les dejo como realizar estos calculos manualmente
Les cuento un poco de mi, Soy Esteban Prieto vivo en Argentina – Buenos Aires, actualmente trabajo como System Engineer en VMware, soy Veeam Vanguard 2019/21 Class 💯 y Veeam Legend First Class 2021 👨🎓.
Lo primero que descubrí siendo parte de las 2 comunidades mas importantes de tecnología, es que el éxito de cada una de ellas se debe a la pasión de quienes las componen, y ese es un gran diferencial. Personas que viven en distintas partes del mundo, otras culturas, todos apasionados y dispuestos a participar en las distintas actividades durante el año. Dos increíbles personas se encargan de unir a estos paises a pesar de la distancia fisica, Nikola Pejkova por parte de Veeam Vanguard y Kseniya Zvereva por parte de Veeam Legends, sumando a Rick Vanover como gran impulsor y a quien tuve el placer de conocer.
Rick
Kseniya
Nikola
Voy a destacar mi experiencia en el año 2019, en el Vanguard Summit en Praga 🏰 , donde nos reunimos todos juntos: estuvo el equipo de Veeam Product Strategy acompañado también con miembros del equipo de R&D toda una semana en Praga junto con Vanguards de todo el mundo 🌎 para compartir las últimas actualizaciones del lanzamiento de la v10 VB&R, lo cual fue super divertido y ¡todos lo pasamos increíble! 🕺
Ahora desde el COVID, hacemos reuniones semanales regulares en el calendario, es la llamada «Veeam Vanguard Social» 🤓
La experencia del SWAG 🎁 es fantástica y cada año se superan. Se preocupan mucho por mantenernos contentos
Aquí mantenemos conversaciones y nos brindan a los usuarios un lugar único donde podemos compartir las mejores prácticas, participar en Veeam User Groups, crecer como profesionales de Veeam, completando capacitaciónes gratuitas bajo demanda a través de Veeam University y divertirse, hay reconocimientos y recompensas. Los invito a todos a unirse, donde cada granito que aportan les suma puntos para convertirse en un nuevo Veeam Legends !!
En ambas comunidades nos tienen muy encuenta y podemos influir en el desarrollo de productos y soluciones de Veeam: ¡tenemos un impacto real dentro de la comunidad!
En cada proyecto de nuevas versiones nos hacen parte y para el lanzamiento de la gran V11 de Veeam Backup & Replication tuvimos acceso a todos los betas, dando nuestro feedback de cada feature nuevo. Esto nos motiva aún mas para dar a conocer y promover a todos los clientes de Veeam cada mejora que obtendran.
Para finalizar agrego otros beneficios que tenemos por ser parte de los programas:
Una invitación al grupo privado Veeam Legends / Vanguard
Permiso para usar el logotipo de Veeam Legends/Vanguard en tarjetas, sitio web, etc. durante un año
Seminarios web privados con socios de Veeam
Acceso a NFR, betas privadas y sesiones informativas previas al lanzamiento
Acceso a los equipos de productos de Veeam
Cuando hago un review de todo lo que transité estos años con Veeam no puedo dejar afuera a cada uno que aporto un poquito para impulsarme a llegar hasta aquí. Gracias a toda la oficina de Veeam Argentina, en espacial a Ailin Puy y a Sara Wilson, me hacen sentir siempre uno mas. Mi mejor experiencia es seguir conociendo personas espectaculares.
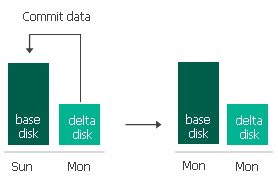
Una política de retención define durante cuánto tiempo Veeam Backup & Replication debe almacenar los puntos de restauración para las réplicas de VM. Veeam Backup & Replication ofrece dos esquemas de políticas de retención:
Veeam Backup & Replication conserva los puntos de restauración a largo plazo durante el número de días especificado en la configuración de la política de CDP . Cuando se excede el período de retención, Veeam Backup & Replication transforma la cadena de replicación de la siguiente manera. El ejemplo muestra cómo funciona la retención a largo plazo para una réplica de VM con un disco virtual.
Veeam Backup & Replication comprueba si la cadena de replicación contiene puntos de restauración a largo plazo obsoletos.
Si existe un punto de restauración desactualizado, Veeam Backup & Replication reconstruye el archivo que contiene datos para el disco base ( <disk_name> – flat.vmdk) para incluir datos del archivo que contiene datos para el disco delta ( <disk_name> – <index > .vmdk). Para hacer eso, Veeam Backup & Replication se compromete en los datos del archivo del disco base desde el archivo delta disk más antiguo. De esta manera, el archivo del disco base ‘avanza’ en la cadena de replicación
3. Veeam Backup & Replication elimina el archivo de disco delta más antiguo de la cadena como redundante; estos datos ya se han incluido en el archivo de disco base.
Retención a corto plazo
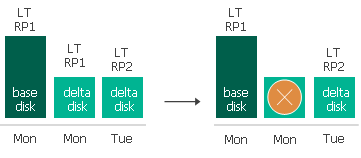
Veeam Backup & Replication conserva los puntos de restauración a corto plazo durante el número de horas especificado en la configuración de la política de CDP . Cuando se excede el período de retención, Veeam Backup & Replication transforma la cadena de replicación de la siguiente manera. El ejemplo muestra cómo funciona la retención a corto plazo para una réplica de VM con un disco virtual.
Veeam Backup & Replication comprueba si la cadena de replicación contiene puntos de restauración a corto plazo obsoletos.
Si existe un punto de restauración desactualizado, Veeam Backup & Replication envía los datos del punto de restauración desde el archivo de registro de transacciones (.tlog) al archivo de disco base o delta más cercano ( <nombre_disco> – flat.vmdk o <nombre_disco> – <índice> .vmdk).
Si el archivo de registro de transacciones no contiene datos para otros puntos de restauración, Veeam Backup & Replication elimina el archivo de registro de transacciones como redundante; sus datos ya se han comprometido en el archivo de disco base o delta.
NOTA
Veeam Backup & Replication puede almacenar puntos de restauración a corto plazo durante un período más largo que el especificado en la política de retención a corto plazo.
Hoy tengo la felicidad que me han elegido para el programa de Veeam Legends, una gran forma de compartir ideas, dudas, y conocimiento tecnico de Veeam. Un honor seguir contribuyendo desde las dos comunidades Veeam Legends y Veeam Vanguard !!
Les doy una descripción general del programa.
Quiénes son Veeam Legends?
Veeam Legends son usuarios de Veeam y expertos en la industria de protección de datos que sienten pasión por la tecnología, la innovación y están ansiosos por desarrollar aún más su carrera, mientras comparten sus experiencias con la comunidad. Como usuarios ávidos de Veeam, participan en varios proyectos comunitarios, impulsan los locales de grupos de usuarios Veeam y también pueden influir en el desarrollo de productos y soluciones de Veeam: ¡tienen un impacto real dentro de la comunidad! Aparte de eso, Veeam Legends siempre está ansioso por ayudar a sus compañeros y conectarse con otros miembros de la comunidad.
¿Cómo me convierto en Veeam Legend?
Únase al Centro de recursos de la comunidad de Veeam y participe en los proyectos de la comunidad de Veeam: ya sea que tenga muchas ideas de productos o si es un creador de contenido fructífero , ¡nuestro sistema de recompensas lo cuenta todo! Recibirá puntos e insignias por diferentes actividades dentro del Veeam Community Resource Hub, así que observe su perfil. Veeam Legends se anunciará al final de cada año. ¿Sigues aquí? ¡Anímate y comienza tu viaje ahora!
¿Qué se necesita para ser Veeam Legend?
Apreciamos a todos los colaboradores de la comunidad y realmente creemos en el poder de la comunidad. Esperamos que Veeam Legend contribuya constantemente a la comunidad técnica y siga expresando su pasión por nuestros productos con ellos para conservar su título de Veeam Legend. Los puntos se restablecen anualmente para todos los niveles, pero las insignias y rangos permanecen.
Beneficios del programa Veeam Legends:
Una invitación al grupo privado Veeam Legends
Permiso para usar el logotipo de Veeam Legends en tarjetas, sitio web, etc. durante un año
Seminarios web privados con socios de Veeam
Acceso a NFR, betas privadas y sesiones informativas previas al lanzamiento
Acceso a los equipos de productos de Veeam
Destacado en un directorio en línea público de Veeam Legends
Botín de Veeam Legends
¿Cómo puedo realizar un seguimiento de mi estado y logros?
Para realizar un seguimiento de sus logros, esté atento a su perfil: verá la cantidad de puntos e insignias obtenidos. La tabla de clasificación le mostrará los miembros de la comunidad más proactivos de todos los tiempos y semanalmente.
Descripción general del sistema de recompensas
Estos son los principios clave del sistema de recompensas de Veeam Legends:
El sistema de recompensas consta de puntos, insignias, rangos y clasificación.
Veeam Legend es una designación dentro del programa
Veeam Legends debería ofrecer cierto nivel de contribución por mes para mantener el título
Los puntos se restablecen anualmente para los niveles; Quedan insignias y rangos
Código de conducta de Veeam Legends
La comunidad es lo primero: siempre hemos puesto a la comunidad de Veeam en primer lugar en todo lo que hacemos. Nos gustaría que Veeam Legends fuera una continuación de los valores y creencias de Veeam al comportarse con respeto al interactuar con cualquier persona dentro y fuera de la comunidad.
Aquí hay algunas reglas de la casa que esperamos seguir para asegurarnos de que este espacio siga siendo amigable:
No usar lenguaje profano, ofensivo, odioso, acosador, amenazante, violento u obsceno.
No se permiten comentarios discriminatorios que incluyan raza, etnia, religión, género, discapacidad, orientación sexual o creencias políticas.
Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ ) Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para…
Todo lo mostrado aquí está incluido en todas las suscripciones de OpenShift. Al migrar desde VMware, una de las primeras dudas es cómo se trasladan los conceptos de red. Este post lo explica visualmente. Figure 1: Virtual Machine Networking in OpenShift Las VMs pueden conectarse a: Interfaces soportadas: Esto permite emular redes como las de VMware…
En este tema, le mostraré cómo usar esta herramienta Veeam Networking Port Tool para VBR v10
Descargo de responsabilidad Esta herramienta utiliza los datos más recientes de la Guía del usuario de Veeam. Recomendamos a los usuarios que verifiquen los resultados con la guía del usuario, consulten a un ingeniero de sistemas o arquitecto de soluciones de Veeam. Los números de puertos cambian, no podemos responsabilizarnos por ningún cambio dentro del software de Veeam que se haya realizado después de la fecha que se muestra a continuación. Esta designación de puerto es correcta a partir de agosto de 2020
Esta herramienta fue desarrollada para simplificar la identificación de puertos requeridos por el software Veeam. Estos deben estar operativos en su firewall entre cada componente de la infraestructura de Veeam Backup and Replication cuando elija usarlos
Cómo utilizar esta herramienta
Prepárate . Sepa qué servidores planea usar en el diseño y qué desea hacer con ellos, por ejemplo, tenga una lista de nombres de servidor, direcciones IP y qué roles de Veeam que le gustaría usar en cada servidor. Desde el punto de vista de la seguridad, en realidad no necesitamos conocer los nombres reales, puede crear una lista de nombres de servidor que podría ser del 1 al 100 siempre que sepa lo que representan en su diseño, lo mismo para las direcciones IP, no hay datos almacenados con esta herramienta. Todo está en la caché de su navegador únicamente.
Pasos y páginas
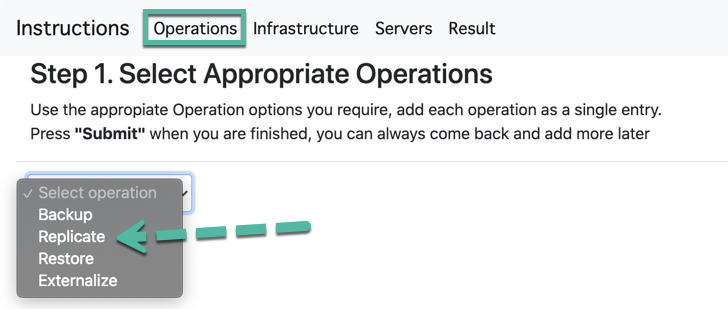
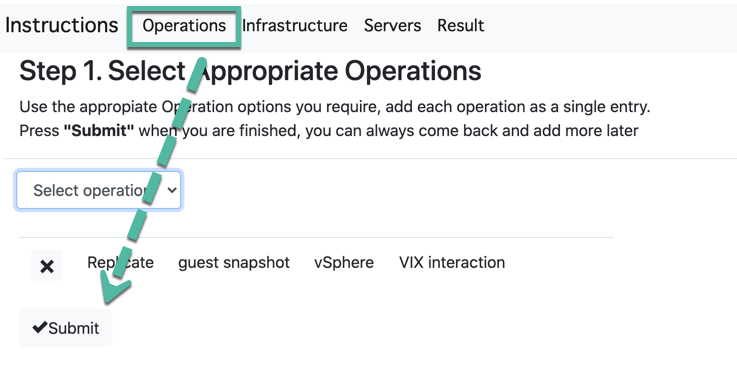
Paso 1. Operaciones
Seleccione las operaciones que desea realizar dentro de la infraestructura de Veeam.
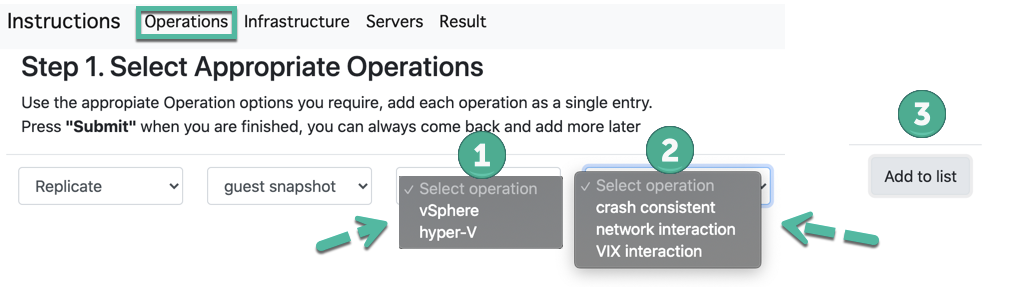
Seleccione cada operación y cree una lista de cada opción en esta página, siga cada paso a medida que se desarrolla y una vez que aparezca «Agregar a la lista», estará completo. Puede haber muchas opciones para cada operación, así que lea cada opción con atención. Si desea agregar varias opciones similares, agregue cada una por separado, en cualquier momento puede volver a esta página y agregar operaciones adicionales, la herramienta es dinámica.
No olvide presionar «Enviar» .
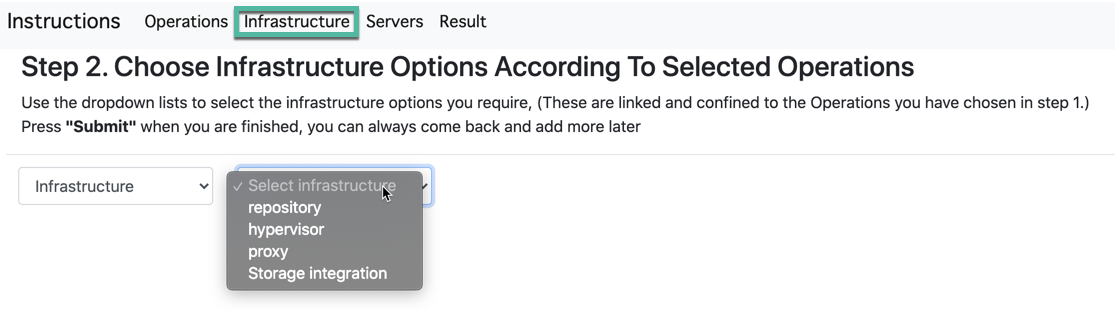
Paso 2. Infraestructura
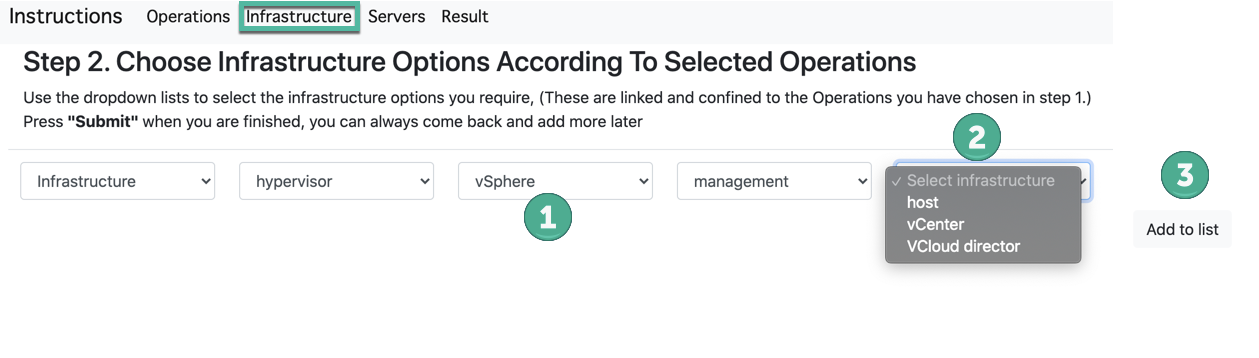
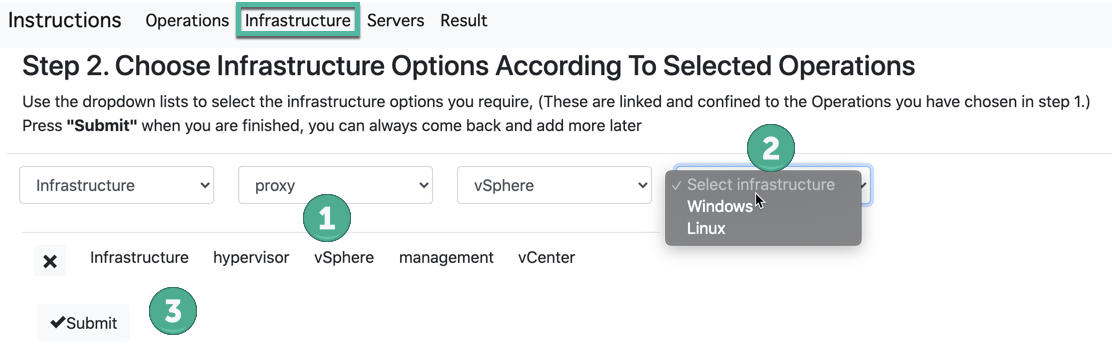
La página de Infraestructura ofrece los roles de componentes de infraestructura de Veeam que desea agregar, como Proxy, Repositorios, Hipervisor u opciones de almacenamiento. Agregue cada componente según sea necesario para crear las opciones necesarias para el diseño. Continúe agregando cada opción hasta que tenga una lista completa de las opciones que necesitará. En este ejemplo, elijo Hypervisor
y agregué un vCenter como Infra del Hypervisor
y elegimos un proxy para estas operaciones.
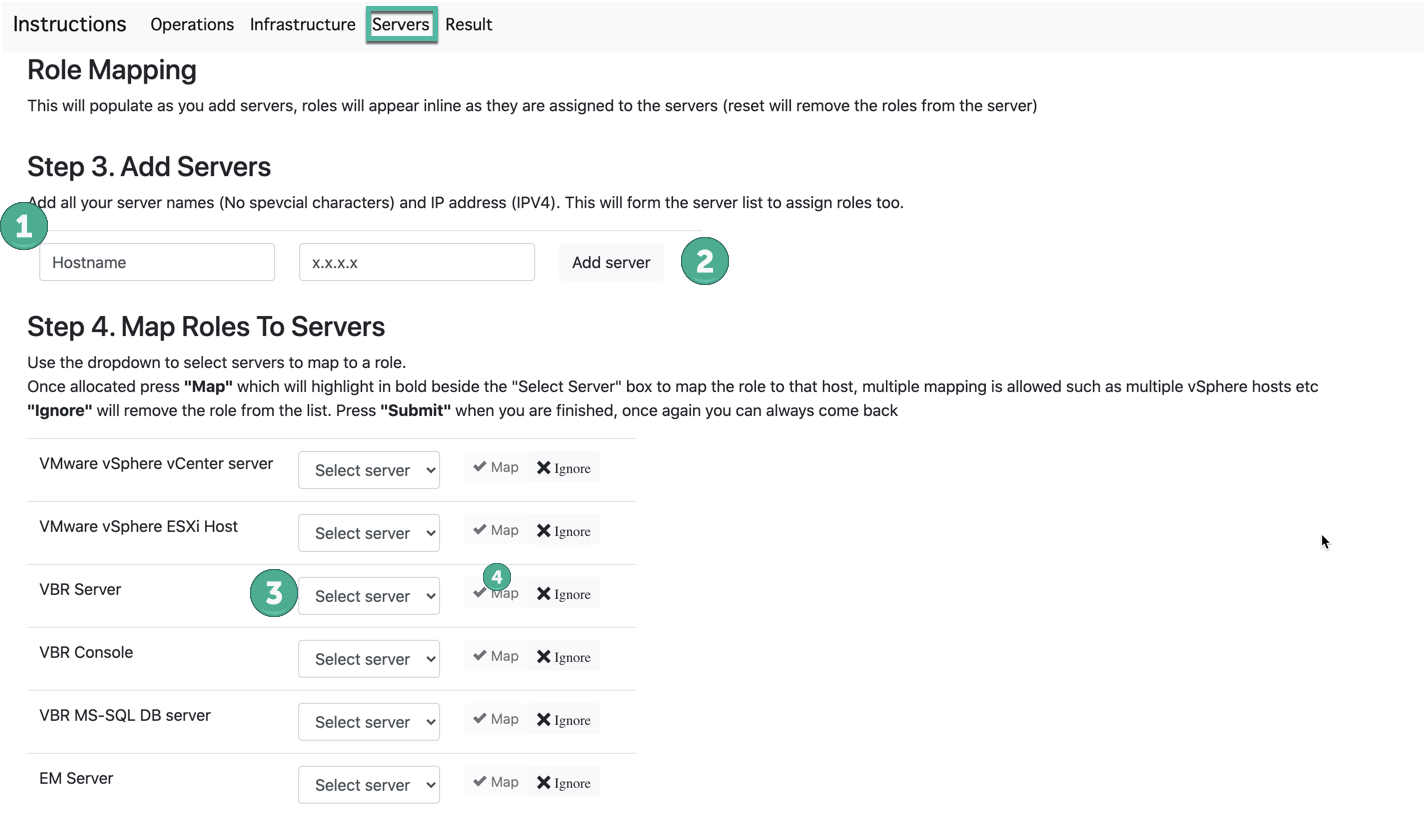
Servers
Hay dos pasos en esta página.
Parte superior de la página «Asignación de funciones» enumera los servidores que ha agregado y las funciones asignadas que se les asignaron.
Paso 3. Agregar servidores Paso 4. Asignar roles a servidores
Cuando seleccionamos las operaciones, la infraestructura con sus opciones, necesitamos poder asignarlas a los servidores para que podamos comprender cómo encajan.
Paso 3 . Agregar servidores
Esta es la entrada de nuestros nombres de servidor y direcciones IP reales que planeamos usar, lo que es importante con las direcciones IP son solo los conceptos básicos de las mismas subredes. Con esta lista, asignaremos los roles de Veeam a cada servidor, por lo que debe ser completo. Mire hacia abajo a la sección de roles del mapa y podrá ver qué roles están disponibles. También será necesario acceder a un servidor de autenticación, por lo que también será necesario agregarlo para la función asignada.
Paso 4. Asignación de roles
En este punto tenemos roles y hemos agregado servidores, ahora necesitamos agregar cada rol a un servidor designado. usando el cuadro desplegable al lado de un rol en particular, puede elegir un servidor de la lista, una vez seleccionado el «MAPA» El botón se resaltará y puede presionarlo para asignar ese rol a ese servidor en la página, la asignación de roles en la parte superior de la página cambiará para reflejar que el servidor ahora tiene asignado el rol. Los servidores pueden tener múltiples roles y usted puede asignar el mismo servidor a otros roles para reflejar su diseño con precisión. Si ve un rol que no usará pero que se agregó automáticamente como «EM Server» (Administrador corporativo), puede presionar ignorar y el rol se eliminará por completo (esto es irreversible actualmente). Una vez que haya verificado que todos los roles están asignados correctamente a los servidores, puede enviar las opciones a la configuración.
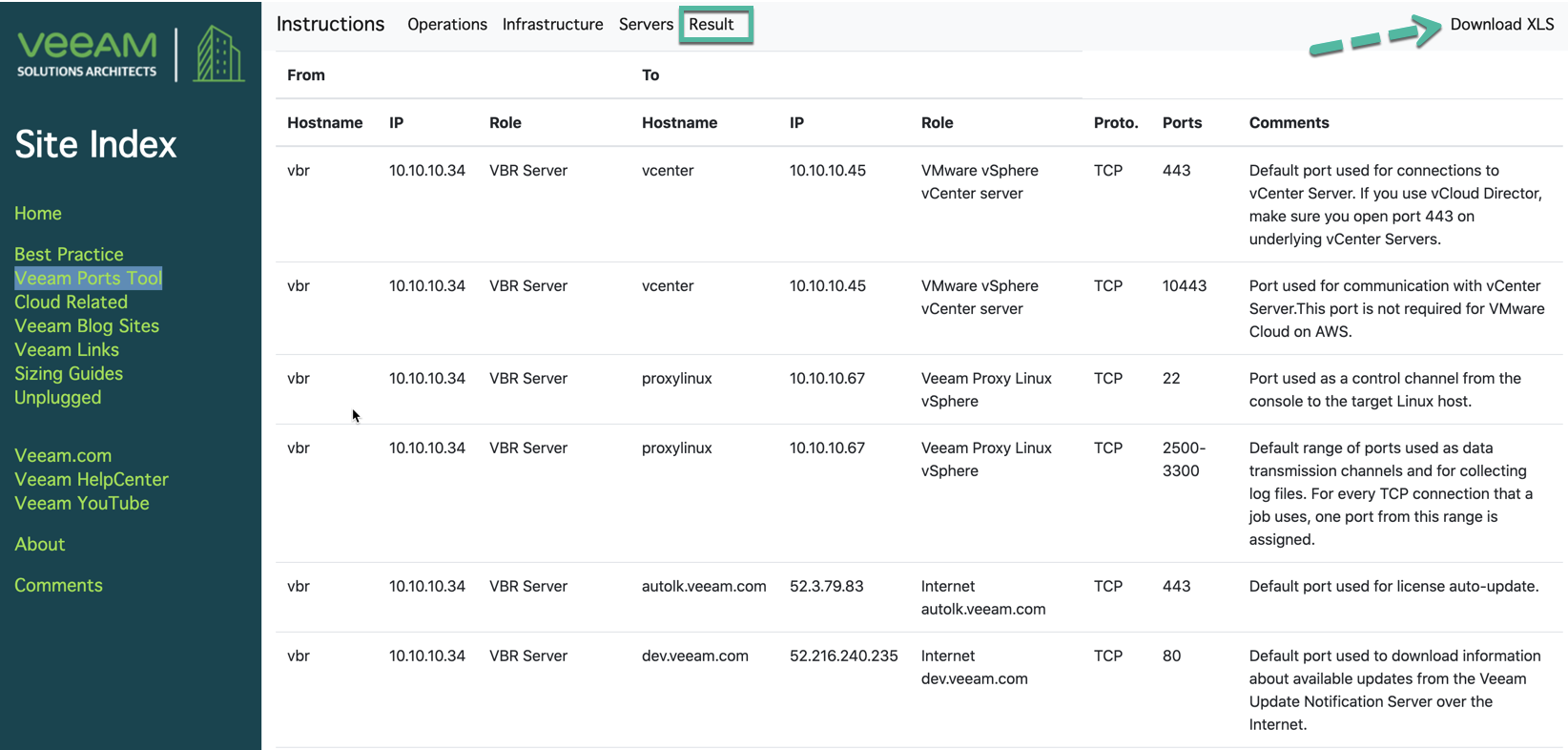
Resultado
Tienes todos los puertos que usarás en estas operaciones y puedes exportar a XLS
Todos los que administramos VMware sabemos de lo que hablamos cuando nombramos CPU Ready (%RDY) como Métrica de Rendimiento, entonces explicare que es, y como se mide en Openshift Virtualization. ¿Qué es CPU Ready? El término “CPU Ready” puede dar lugar a malentendidos. Se podría pensar que representa la cantidad de CPU lista para ser…
Buenas a todos, les dejo por aqui el 🎁 de este super Book que nos trae todas las buenas practicas de Performance en vSphere 8.0 U2. Download Aquí Book Este libro consta de los siguientes capítulos: Audiencia Prevista: Este libro está dirigido a administradores de sistemas que estén planificando una implementación de VMware vSphere 8.0 Actualización 2 y…
Hola !! les traigo una herramienta super util para todos, vSAM recopila y resume la información de implementación de productos vSphere. Requiere las API de vSphere para los datos de implementación y produce un informe en PDF que el cliente puede consultar como parte de su proceso de revisión y planificación de la infraestructura Podes…
En este tema veremos sobre el diseño del repositorio.
Necesitamos considerar
La recomendación clave es seguir la regla 3 -2-1 .
Calcule 1 núcleo y 4 GB de RAM por repository task slot. El mínimo recomendado para un repositorio es de 2 núcleos y 8 GB de RAM.
Dimensionamiento
La cantidad recomendada de CPU para un repositorio es de 1 núcleo por ranura de tarea configurada concurrente en un servidor de repositorio. Configure como mínimo un servidor de repositorio de 2 núcleos y 8 GB de RAM para permitir que el sistema operativo responda mejor.
Al dimensionar los espacios de tareas en un repositorio, debe comprender cuándo y cuántos espacios de tareas se consumen. Cualquier proceso de escritura consumirá un espacio de tarea. Por lo tanto, hacer una copia de seguridad de 10 máquinas virtuales en un trabajo utilizando cadenas de copia de seguridad por trabajo solo escribirá un archivo (VBK / VIB) al final, por lo que consume una ranura de tarea.
Ejecutar el mismo trabajo de respaldo con archivos de respaldo por VM creará un archivo por VM y, por lo tanto, puede aprovechar hasta 10 ranuras de tareas (cuando estén disponibles).
Los trabajos de copia de respaldo, los respaldos de agentes y los trabajos de complementos también consumen espacios de tareas y deben tenerse en cuenta.
Una tarea en el nivel de repositorio se consume de manera diferente que las tareas en el nivel de proxy. Si los «archivos de respaldo por VM» están habilitados en el repositorio, cada VM procesada simultáneamente consumirá una tarea de repositorio, mientras que cada disco virtual de esta VM consumirá una tarea de proxy (la proporción típica es de 3 discos por VM)
Si los «archivos de copia de seguridad por máquina virtual» están deshabilitados , una sola tarea de copia de seguridad consumirá solo una tarea de repositorio, independientemente de la cantidad de máquinas virtuales que esté procesando la tarea. Pero la cantidad de tareas de proxy consumidas seguirá siendo la misma (una tarea por cada disco virtual).
Ejemplo
Si el requisito principal para el proxy es 16 núcleos para el incremental, los núcleos para el repositorio serán 5 según una proporción de disco a máquina virtual de 3: 1(redondeado). Para calcular la RAM, esto se multiplica por el requisito de RAM de 4 GB por núcleo, lo que da como resultado 20 GB.
Cuando el resultado de su cálculo sea un servidor (virtual) muy pequeño, considere recursos adicionales para la sobrecarga del sistema operativo (1 Core / 4GB RAM adicional debería ser suficiente). Normalmente, los tamaños tienden a ser de un mínimo de 4 núcleos / 16 GB para servidores virtuales o servidores físicos con> 10 núcleos y 64 GB de RAM donde de todos modos hay suficientes recursos disponibles para el sistema operativo.
¿Qué pasa con ReFS?
Al usar el sistema de archivos Windows ReFS, la recomendación es agregar 0.5 GB de RAM por TB de almacenamiento ReFS. Sin embargo, no tiene que escalar esto indefinidamente. 128 GB de RAM suelen ser suficientes para los requisitos de tareas, SO y ReFS si el tamaño total del volumen de ReFS del servidor es inferior a ~ 200 TB. Según el tamaño de ReFS o los requisitos de la tarea, es posible que desee agregar más memoria, pero no debería ser necesario superar los 256 GB.

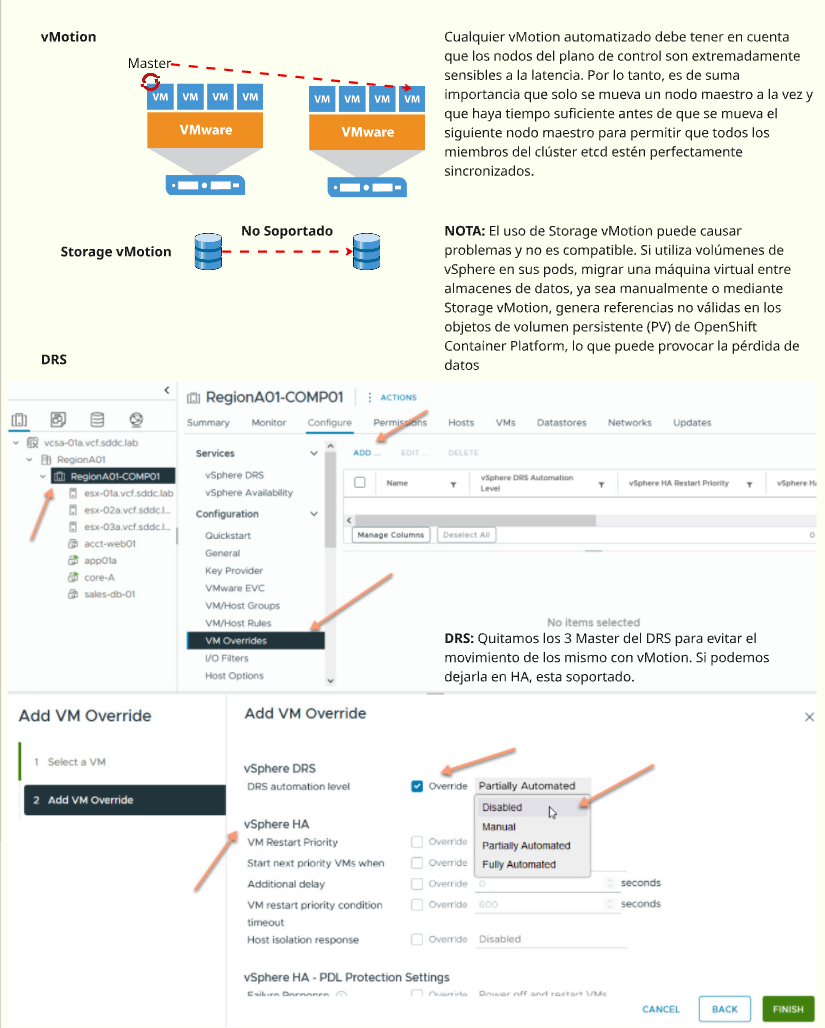




























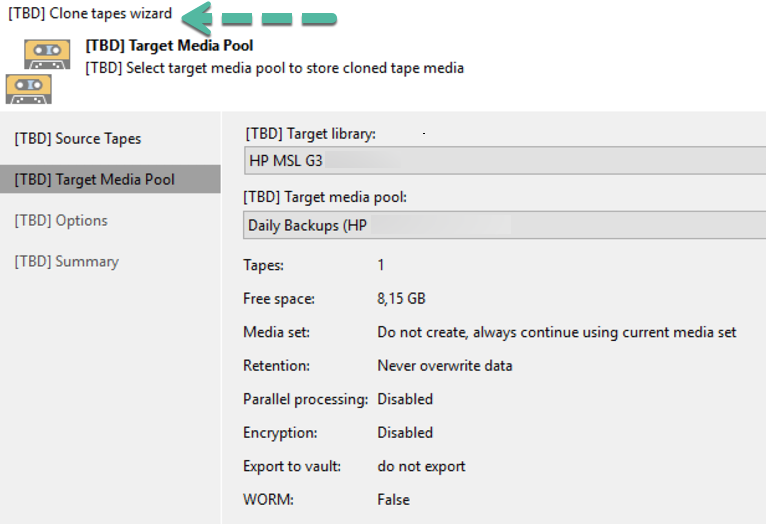
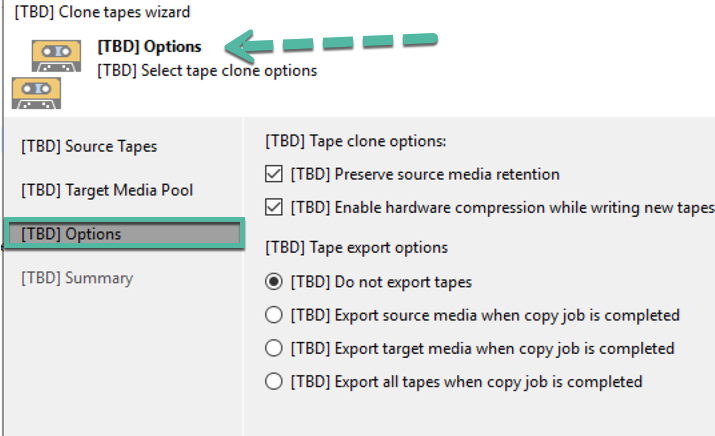







 Espero te sea de utilidad
Espero te sea de utilidad 
