vSphere con alta disponibilidad de Tanzu 🤓
Comencemos analizando genéricamente las soluciones de nube pública, ya que ofrecen una plantilla para proporcionar infraestructura y aislamiento de servicios críticos. Los recursos de la nube pública se alojan en regiones geográficas segmentadas en zonas de disponibilidad (AZ) que proporcionan un conjunto de servicios e infraestructura física aislados. Los recursos pueden ser regionales o basados en AZ, sin embargo, la mayoría están contenidos en una única zona de disponibilidad. Por ejemplo, los nodos de máquina virtual que componen un clúster de Kubernetes podrían ser específicos de AZ y solo podrían adjuntar un volumen persistente que estuviera en la misma zona. Las direcciones IP estáticas o las imágenes de VM pueden ser regionales y estar disponibles en todas las zonas. Las AZ proporcionan una capa de abstracción sobre la infraestructura física que las respalda. Esa infraestructura está diseñada para garantizar el aislamiento de la mayoría de las fallas de infraestructura física y de software. La mayoría de las AZ están diseñadas con sus propios planos de energía, refrigeración, redes y control aislados de otras zonas.
Los recursos de vSphere se alojan en una infraestructura física que se puede aislar en vSphere Clusters y administrar mediante vCenter. A efectos de comparación con la nube pública, podemos pensar en un clúster de vSphere como una zona de disponibilidad (AZ). Los hosts ESXi se agrupan en racks de centros de datos físicos, conectados entre sí, y a otros racks, a través de una serie de conmutadores de red. Las organizaciones toman decisiones sobre si alinear los racks con los clústeres de vSphere o distribuir los hosts de un clúster entre los racks. El mapeo uno a uno entre clústeres y racks proporciona aislamiento y comunicación de baja latencia entre las aplicaciones que se ejecutan en el clúster, a expensas de la disponibilidad en el caso de una conmutación fallida.
vSphere with Tanzu actualmente admite la implementación de clústeres de Supervisor y Tanzu Kubernetes Grid (TKG) en un solo clúster de vSphere. Piense en esto como una implementación de una sola zona de disponibilidad. Una implementación de una sola zona de disponibilidad no significa que no haya alta disponibilidad. Como se describe a continuación, vSphere proporciona un conjunto de capacidades para promover la disponibilidad de los clústeres de Tanzu Kubernetes Grid (TKG) que se ejecutan en una sola AZ.
Veamos la capacidad en la plataforma que admite alta disponibilidad, luego definamos un conjunto de escenarios de falla dentro de una implementación de vSphere con Tanzu y analicemos los enfoques para aumentar la disponibilidad.
Plano de control de múltiples nodos de clúster con host Anti-Affinity y HA
Supervisor Cluster proporciona la API de Kubernetes para implementar los clústeres de vSphere Pods y TKG. Es un servicio del sistema que debe estar disponible para la operación de clústeres y servicios de TKG implementados como operadores de Kubernetes. Para garantizar la disponibilidad, hemos implementado una configuración de varios controladores. Tanto el supervisor como los controladores de clúster de TKG están configurados en una implementación apilada con el servidor Kube-API y etcd disponibles en cada máquina virtual. Cada plano de control tiene un balanceador de carga que enruta el tráfico a las API de Kube en cada nodo del controlador. La programación de los nodos del plano de control se realiza a través de vSphere 7.0 VMware vSphere® Distributed Resource Scheduler ™ (DRS). vSphere 7.0 DRS es más rápido y liviano, lo que garantiza una ubicación rápida entre los hosts, utilizando una política de computación suave de antiafinidad para separar los controladores en hosts separados cuando sea posible. La antiafinidad garantiza que una sola falla del controlador no afecte la disponibilidad del clúster.
Además, vSphere HA proporciona alta disponibilidad para los controladores fallidos al monitorear los eventos de falla y volver a encender las máquinas virtuales. En caso de falla del host, las VM, tanto los nodos Supervisor como TKG, se reinician en otro host disponible, lo que reduce drásticamente el tiempo que el clúster aún disponible se ejecuta con capacidad disminuida. Los Supervisor Controllers son administrados por el ciclo de vida de vSphere Agent Manager (EAM) y los administradores no pueden apagarlos fácilmente; sin embargo, si se apagan, se reiniciarán inmediatamente en el mismo host.
Pods y Daemons del sistema de clústeres
Systemd es el sistema de inicio para la distribución de PhotonOS linux que alimenta los nodos Supervisor y TKG Cluster. Systemd proporciona supervisión de procesos y reiniciará automáticamente cualquier daemons fallido crítico, como el kubelet de Kubernetes.
Los pods del sistema de Kubernetes, los pods de recursos personalizados de VMware y los controladores se implementan como conjuntos de réplicas (o DaemonSets en el contexto de los clústeres de TKG) supervisados por otros controladores de Kubernetes y los contenedores los volverán a crear en caso de falla. Los procesos y pods que componen los clústeres Supervisor y TKG se implementan con mayor frecuencia con múltiples réplicas, por lo que continúan estando disponibles incluso durante la reconciliación de un Pod fallido. La implementación en términos del uso de DaemonSets vs ReplicaSets es diferente entre los clústeres de Supervisor y TKG, pero la disponibilidad de los pods del sistema individuales es similar
Supervisor y equilibrador de carga del controlador de clúster TKG
Como se mencionó anteriormente, los clústeres de supervisor y TKG se implementan como un conjunto de tres controladores. En el caso de los clústeres de TKG, los desarrolladores pueden elegir una implementación de un solo controlador si los recursos están limitados. El acceso a kube-api se dirige a una IP virtual de Load Balancer y se distribuye entre los puntos finales de API disponibles. La pérdida de un nodo del plano de control no afecta la disponibilidad del clúster. Los balanceadores de carga basados en NSX se ejecutan en nodos perimetrales que se pueden implementar en una configuración activa / activa, lo que garantiza la disponibilidad de la IP virtual que los desarrolladores usarán para acceder a los clústeres.
Disponibilidad de almacenamiento en clúster
Los clientes tienen la opción de habilitar VMware vSAN para proporcionar almacenamiento compartido de alta disponibilidad para los clústeres de Supervisor y TKG. vSAN combina el almacenamiento que es local para los hosts en una matriz de almacenamiento virtual que se puede configurar con las necesidades de redundancia del entorno. Los niveles de RAID se implementan en todos los hosts y brindan disponibilidad en los casos en que fallan los hosts individuales. vSAN es nativo del hipervisor ESXi y, por lo tanto, no se ejecuta como un conjunto de dispositivos de almacenamiento que podrían competir con las VM del clúster de Kubernetes por los recursos.
Disponibilidad de vSphere Pods
Los clientes que necesitan el aislamiento de una máquina virtual desde una perspectiva de seguridad y rendimiento, mientras desean orquestar la carga de trabajo a través de Kubernetes, pueden elegir vSphere Pods. Los operadores del sistema y de terceros también se pueden implementar como pods de vSphere. Se ejecutan en una máquina virtual en tiempo de ejecución de contenedor directamente en hosts ESXi y se comportan como cualquier otro pod. La disponibilidad se administra a través de objetos estándar de Kubernetes y sigue el patrón de Kubernetes para manejar fallas de pod. Cree una implementación con varias réplicas definidas y el controlador observará los pods fallidos y los volverá a crear. Las fallas de host harían que los vSphere Pods se volvieran a crear en nuevos hosts. Este patrón no usa vSphere HA, sino que aprovecha los controladores de Kubernetes para manejar fallas.
Escenarios de falla de infraestructura y software
Analizamos la capacidad central dentro de la plataforma y ahora definiremos un conjunto de escenarios de falla dentro de una implementación de vSphere con Tanzu, luego analizaremos los enfoques para aumentar la disponibilidad en cada escenario.
Fallo del componente del clúster de Kubernetes
- Fallo del proceso del nodo de Kubernetes
- Fallo del pod del sistema de Kubernetes
- Máquina virtual apagada
Cuando un controlador o un nodo trabajador deja de estar disponible, los pods del sistema se volverán a crear en uno de los otros nodos disponibles. Los procesos fallidos de Linux son monitoreados y reiniciados por el sistema de inicio systemd. Esto es cierto tanto para el plano de control de TKG como para los nodos de trabajo, así como para el plano de control del supervisor. Los nodos Supervisor Worker son hosts ESXi reales, no ejecutan systemd y manejan las fallas del proceso de manera diferente. Las máquinas virtuales que se apagan se reinician automáticamente. El plano de control se implementa como un conjunto de 3 controladores, con una IP virtual de Load Balancer como el punto final de Kube-API para garantizar que durante el tiempo necesario para remediar la interrupción, el clúster todavía esté disponible. La corrección de los nodos de trabajo de TKG se maneja mediante el uso integrado de la capacidad MachineHeatlhCheck en ClusterAPI V1Alpha3.
Interrupción del host
- Error de host
- Reinicio del host
La falta de disponibilidad de un host ESXi puede deberse a un breve reinicio o podría estar relacionada con una falla real del hardware. Al reiniciar, todas las VM del controlador y del nodo se reinician automáticamente en el host. Si el reinicio tarda más que el umbral de tiempo de espera de latido de HA, las VM se programan para su ubicación en otros hosts disponibles y se encienden. Las reglas de antiafinidad se mantendrán si los recursos lo permiten. En cualquier caso, los clústeres todavía están disponibles porque tienen varios nodos de controlador ubicados en hosts ESXi separados y se accede a ellos a través de un equilibrador de carga y pueden sobrevivir a la pérdida de un controlador.
Interrupción del estante
- Fallo del interruptor de la parte superior del bastidor
Los hosts están organizados en racks físicos en el centro de datos. Los hosts en un rack se conectan a través de un conmutador Top of Rack y además se conectan a conmutadores de agregación adicionales. La pérdida de un conmutador, matriz de almacenamiento o alimentación podría hacer que un rack completo no esté disponible. La disponibilidad de un supervisor o clúster TKG depende de cómo se alinean los hosts con los racks. Algunos clientes colocarán todos los hosts en un clúster de vSphere en el mismo rack, lo que esencialmente hará que ese rack físico sea una zona de disponibilidad (AZ). La falla del bastidor haría que el Supervisor Cluster y todos los clústeres TKG no estuvieran disponibles. Otra opción es crear clústeres de vSphere a partir de hosts que residen en varios racks. Esta configuración garantiza que una sola falla de bastidor no haga que todos los hosts de vSphere Cluster no estén disponibles y aumenta la probabilidad de que el plano de control permanezca disponible.
Actualmente, el Programador de recursos distribuidos (DRS) no reconoce el bastidor. Esto significa que las reglas de antiafinidad para las máquinas virtuales del plano de control garantizarían la separación de hosts, pero no necesariamente garantizarían que los hosts estuvieran en racks separados. Se está trabajando para proporcionar una programación basada en rack que mejoraría esta disponibilidad.
Fallo de la matriz de almacenamiento
Los clústeres de supervisor y TKG requieren almacenamiento compartido para permitir que los volúmenes persistentes sean accesibles a los pods que se pueden colocar en cualquier nodo, que podría residir en cualquier host. Tanto vSAN como los arreglos de almacenamiento tradicionales admiten varias configuraciones RAID que garantizan la disponibilidad de datos en caso de corrupción de discos individuales. vSAN agrega almacenamiento local adjunto a hosts físicos y también puede permanecer disponible si se produce una falla de host o incluso potencialmente de un rack.
Los clústeres extensibles de vSAN también brindarán la capacidad de dividir un único clúster de vSphere en dominios de fallas específicos de almacenamiento separados. Esto permitiría la disponibilidad de datos incluso con la pérdida de todo el dominio. Con hosts físicos distribuidos en varios racks, los volúmenes persistentes permanecerían disponibles durante las fallas tanto del host como del rack.
Falla de red
La redundancia física está integrada en la mayoría de los entornos de red de producción que brindan disponibilidad a través de fallas de hardware físico. Cuando se implementan con NSX-T, los clústeres Supervisor y TKG se ejecutan en redes superpuestas que son compatibles con la red física subyacente. Las VM de NSX Edge contienen los Vips de Load Balancer y enrutan el tráfico a los nodos del plano de control del clúster. NSX Edges se puede implementar en una configuración activa / activa que mantendría la red disponible en el caso de una falla del host o de la máquina virtual que afectó a un solo NSX Edge.
Interrupción de vCenter
La disponibilidad de vCenter Server es fundamental para el funcionamiento completamente funcional de los clústeres de Supervisor y TKG. En el caso de una falla de vCenter, todas las máquinas virtuales, tanto el controlador como los nodos, continuarán ejecutándose y serán accesibles aunque con funcionalidad degradada. Los módulos de aplicaciones seguirían ejecutándose, pero la implementación y la gestión del sistema serían limitadas. La autenticación requiere que el servicio de inicio de sesión único devuelva un token de autenticación al archivo de configuración de kubectl. Solo los usuarios que tengan un token no vencido podrán acceder al sistema. Objetos como Load Balancers y PersistentVolumeClaims requieren interacción con vCenter y no se pueden administrar durante el ciclo de vida.
vCenter se puede proteger con vCenter High Availability. vCenter High Availability (vCenter HA) protege no solo contra fallas de hardware y host, sino también contra vCenter Server fallas de aplicaciones de . Al utilizar la conmutación por error automatizada de activo a pasivo, vCenter HA admite alta disponibilidad con un tiempo de inactividad mínimo. Esto aumentaría drásticamente la disponibilidad de los grupos Supervisor y TKG.
Hay un trabajo extenso en proceso para desacoplar los servicios principales de vCenter Server y llevarlos al nivel del clúster. El objetivo es proporcionar siempre una infraestructura que continúe funcionando incluso cuando vCenter tiene una interrupción
Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ ) Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para…
Todo lo mostrado aquí está incluido en todas las suscripciones de OpenShift. Al migrar desde VMware, una de las primeras dudas es cómo se trasladan los conceptos de red. Este post lo explica visualmente. Figure 1: Virtual Machine Networking in OpenShift Las VMs pueden conectarse a: Interfaces soportadas: Esto permite emular redes como las de VMware…











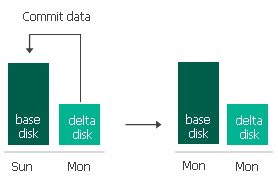











 Espero te sea de utilidad
Espero te sea de utilidad 
 Podemos importar desde estas opciones
Podemos importar desde estas opciones