



Buenas a todos, les dejo por aqui el 🎁 de este super Book que nos trae todas las buenas practicas de Performance en vSphere 8.0 U2.
Download Aquí Book

Este libro consta de los siguientes capítulos:
Audiencia Prevista: Este libro está dirigido a administradores de sistemas que estén planificando una implementación de VMware vSphere 8.0 Actualización 2 y deseen maximizar su rendimiento. El libro asume que el lector ya está familiarizado con los conceptos y la terminología de VMware vSphere.
Espero que lo disfruten !!

Puede inscribir dispositivos que ejecuten cualquier distribución de Linux que se ejecute en arquitecturas x86_64, ARM5 o ARM7 en Workspace ONE UEM.
No esta disponible para entornos On-Prem, Workspace ONE UEM se ha sometido a una rearquitectura completa. Actualmente, esto está disponible en entornos Saas UAT compartidos CN135, CN137 y CN138 y lo implementaremos en entornos Saas dedicados y compartidos después de que se implementen el nuevo Control Plane y UEM v2109

La forma más fácil de validar si la gestión de Linux está habilitada o no en su entorno Workspace ONE UEM es crear un nuevo perfil y comprobar si Linux es una plataforma disponible. Para ello, vaya a Recursos > Perfiles y líneas base > Perfiles > Añadir > Añadir perfil.
Si ve Linux como una plataforma disponible, similar a la siguiente captura de pantalla, su entorno SaaS se ha actualizado y puede inscribir un dispositivo Linux.

📌 Recordemos que iran liberando muchisimas capacidades en cada realease de WS1
Los instaladores se pueden recuperar de las siguientes ubicaciones:
https://packages.vmware.com/wsone

2. Ejecute el instalador del cliente Workspace ONE Intelligent Hub con privilegios de root.
Por ejemplo:
Para el paquete Debian en Ubuntu: $ sudo apt install «/tmp/workspaceone-intelligent-hub-amd64-21.10.0.1.deb»
Para el paquete de RPM en Fedora: $ sudo dnf install workspaceone-intelligent-hub-amd64-21.10.0.1.rpm
Para el paquete RPM en OpenSUSE: $ sudo zypper install workspaceone-intelligent-hub-amd64-21.10.0.1.rpm
Para Tarball (cualquier otra distribución de Linux): 1. Extraiga el paquete usando: $ tar xvf workspaceone-intelligent-hub-<arch>.21.10.0.1.tgz 2. Instale el paquete usando: $ sudo ./install.sh
Nota: Al utilizar Tarball, Ruby debe instalarse manualmente antes de instalar el Intelligent Hub.
3. InscripciónInscriba su dispositivo en Workspace ONE UEM después de la instalación utilizando thews1HubUtil. Elija enviar los detalles de inscripción en un solo comando o por separado. Siga los pasos a continuación para enviarlos en un solo comando.
4. Cambie el directorio al directorio binario Hub bajo el directorio de instalación.
5. Ejecute **ws1HubUtil** e incluya los argumentos de inscripción en orden.
$ sudo ./ws1HubUtil enroll --server https://host.com --user <username> --password <password> --group <organization group id>
Para solicitar a los usuarios las credenciales de inscripción cuando se inscriban, ejecute ws1HubUtil sin estos argumentos adicionales. Consulte Argumentos de línea de comandos admitidos para obtener más detalles antes de intentar una inscripción.
6. Después de una instalación y registro exitosos, el dispositivo Linux aparecerá en la consola WS1 UEM.
7. Desinstalar:
Para desinstalar Intelligent Hub para Linux, puede enviar un comando Enterprise Wipe desde la consola WS1 UEM (para un dispositivo inscrito) o puede desinstalar manualmente el lado del dispositivo. Si el comando de desinstalación se utiliza en el lado del dispositivo inscrito, el dispositivo se cancelará primero.
Para Debian: $ sudo apt eliminar workspaceone-intelligent-hub
Para RPM para Fedora: $ sudo zypper eliminar espacio de trabajoone-intelligent-hub
Para Tarball: $ sudo /opt/Workspace-ONE-Intelligent-Hub/uninstall.sh
Aumentando la resiliencia en clústeres activos-activos bare-metal: arquitectura del plano de control de 4 y 5 nodos ( versión 4.17 ⬆ ) Las organizaciones que ejecutan implementaciones activo-activo en dos ubicaciones , especialmente aquellas que alojan cargas de trabajo con estado, como las máquinas virtuales de OpenShift Virtualization que ejecutan una sola instancia , dependen en gran medida de la infraestructura subyacente para…
Todo lo mostrado aquí está incluido en todas las suscripciones de OpenShift. Al migrar desde VMware, una de las primeras dudas es cómo se trasladan los conceptos de red. Este post lo explica visualmente. Figure 1: Virtual Machine Networking in OpenShift Las VMs pueden conectarse a: Interfaces soportadas: Esto permite emular redes como las de VMware…

📢 Atención #BlockChain#Fans 👀👇
Hemos estado trabajando 👨🏭 duro desde #VMworld del año pasado donde Lanzamos 🚀 #VMware #Blockchain #VMBC
Ahora en el #VMworld2021 🌏
Aprende 🤓 cómo #blockchain está transformando las #industrias 🏭 y ponete al día sobre las finanzas 💰 descentralizadas #DeFi, los #NFT y los intercambios descentralizados #DEX 💳 con estas sesiones:
📌 Sesión VI1553: Obtén una comprensión más profunda de #DeFi 💰 y cómo funciona un #DEX 💳 . Nos sumergiremos en los detalles técnicos y demostraremos una #dApp 💯 de intercambio de #tokens construida sobre #VMBC.
📌 Sesión 1553: Aprende a crear un intercambio de activos digitales #NFT usando #VMBC.
📌 Sesión APP1781: Obtén una visión del futuro de #DevSecOps con Web3 Distributed Ledger Technologies
Estas y mas sesiones en
Registro 👉 https://lnkd.in/gcSKG98p
¡Nos vemos en #VMworld!
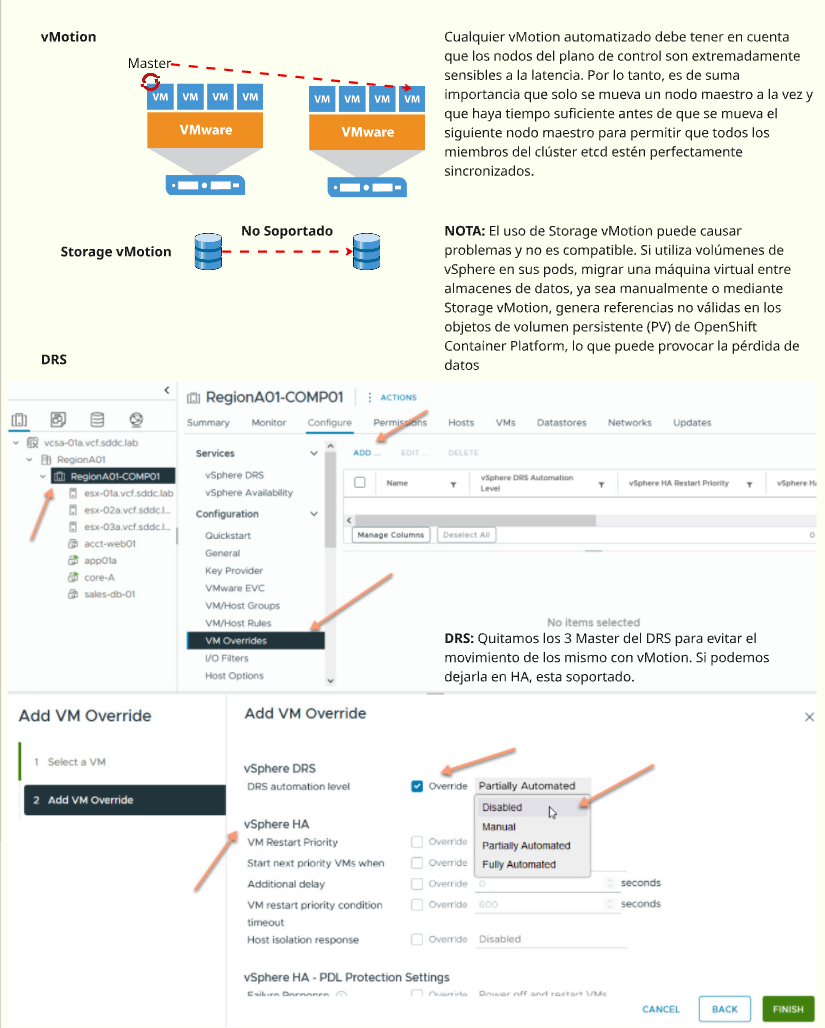
Todos los que administramos VMware sabemos de lo que hablamos cuando nombramos CPU Ready (%RDY) como Métrica de Rendimiento, entonces explicare que es, y como se mide en Openshift Virtualization. ¿Qué es CPU Ready? El término “CPU Ready” puede dar lugar a malentendidos. Se podría pensar que representa la cantidad de CPU lista para ser…
Buenas a todos, les dejo por aqui el 🎁 de este super Book que nos trae todas las buenas practicas de Performance en vSphere 8.0 U2. Download Aquí Book Este libro consta de los siguientes capítulos: Audiencia Prevista: Este libro está dirigido a administradores de sistemas que estén planificando una implementación de VMware vSphere 8.0 Actualización 2 y…
Hola !! les traigo una herramienta super util para todos, vSAM recopila y resume la información de implementación de productos vSphere. Requiere las API de vSphere para los datos de implementación y produce un informe en PDF que el cliente puede consultar como parte de su proceso de revisión y planificación de la infraestructura Podes…

Comencemos analizando genéricamente las soluciones de nube pública, ya que ofrecen una plantilla para proporcionar infraestructura y aislamiento de servicios críticos. Los recursos de la nube pública se alojan en regiones geográficas segmentadas en zonas de disponibilidad (AZ) que proporcionan un conjunto de servicios e infraestructura física aislados. Los recursos pueden ser regionales o basados en AZ, sin embargo, la mayoría están contenidos en una única zona de disponibilidad. Por ejemplo, los nodos de máquina virtual que componen un clúster de Kubernetes podrían ser específicos de AZ y solo podrían adjuntar un volumen persistente que estuviera en la misma zona. Las direcciones IP estáticas o las imágenes de VM pueden ser regionales y estar disponibles en todas las zonas. Las AZ proporcionan una capa de abstracción sobre la infraestructura física que las respalda. Esa infraestructura está diseñada para garantizar el aislamiento de la mayoría de las fallas de infraestructura física y de software. La mayoría de las AZ están diseñadas con sus propios planos de energía, refrigeración, redes y control aislados de otras zonas.
Los recursos de vSphere se alojan en una infraestructura física que se puede aislar en vSphere Clusters y administrar mediante vCenter. A efectos de comparación con la nube pública, podemos pensar en un clúster de vSphere como una zona de disponibilidad (AZ). Los hosts ESXi se agrupan en racks de centros de datos físicos, conectados entre sí, y a otros racks, a través de una serie de conmutadores de red. Las organizaciones toman decisiones sobre si alinear los racks con los clústeres de vSphere o distribuir los hosts de un clúster entre los racks. El mapeo uno a uno entre clústeres y racks proporciona aislamiento y comunicación de baja latencia entre las aplicaciones que se ejecutan en el clúster, a expensas de la disponibilidad en el caso de una conmutación fallida.
vSphere with Tanzu actualmente admite la implementación de clústeres de Supervisor y Tanzu Kubernetes Grid (TKG) en un solo clúster de vSphere. Piense en esto como una implementación de una sola zona de disponibilidad. Una implementación de una sola zona de disponibilidad no significa que no haya alta disponibilidad. Como se describe a continuación, vSphere proporciona un conjunto de capacidades para promover la disponibilidad de los clústeres de Tanzu Kubernetes Grid (TKG) que se ejecutan en una sola AZ.
Veamos la capacidad en la plataforma que admite alta disponibilidad, luego definamos un conjunto de escenarios de falla dentro de una implementación de vSphere con Tanzu y analicemos los enfoques para aumentar la disponibilidad.
Supervisor Cluster proporciona la API de Kubernetes para implementar los clústeres de vSphere Pods y TKG. Es un servicio del sistema que debe estar disponible para la operación de clústeres y servicios de TKG implementados como operadores de Kubernetes. Para garantizar la disponibilidad, hemos implementado una configuración de varios controladores. Tanto el supervisor como los controladores de clúster de TKG están configurados en una implementación apilada con el servidor Kube-API y etcd disponibles en cada máquina virtual. Cada plano de control tiene un balanceador de carga que enruta el tráfico a las API de Kube en cada nodo del controlador. La programación de los nodos del plano de control se realiza a través de vSphere 7.0 VMware vSphere® Distributed Resource Scheduler ™ (DRS). vSphere 7.0 DRS es más rápido y liviano, lo que garantiza una ubicación rápida entre los hosts, utilizando una política de computación suave de antiafinidad para separar los controladores en hosts separados cuando sea posible. La antiafinidad garantiza que una sola falla del controlador no afecte la disponibilidad del clúster.
Además, vSphere HA proporciona alta disponibilidad para los controladores fallidos al monitorear los eventos de falla y volver a encender las máquinas virtuales. En caso de falla del host, las VM, tanto los nodos Supervisor como TKG, se reinician en otro host disponible, lo que reduce drásticamente el tiempo que el clúster aún disponible se ejecuta con capacidad disminuida. Los Supervisor Controllers son administrados por el ciclo de vida de vSphere Agent Manager (EAM) y los administradores no pueden apagarlos fácilmente; sin embargo, si se apagan, se reiniciarán inmediatamente en el mismo host.
Systemd es el sistema de inicio para la distribución de PhotonOS linux que alimenta los nodos Supervisor y TKG Cluster. Systemd proporciona supervisión de procesos y reiniciará automáticamente cualquier daemons fallido crítico, como el kubelet de Kubernetes.
Los pods del sistema de Kubernetes, los pods de recursos personalizados de VMware y los controladores se implementan como conjuntos de réplicas (o DaemonSets en el contexto de los clústeres de TKG) supervisados por otros controladores de Kubernetes y los contenedores los volverán a crear en caso de falla. Los procesos y pods que componen los clústeres Supervisor y TKG se implementan con mayor frecuencia con múltiples réplicas, por lo que continúan estando disponibles incluso durante la reconciliación de un Pod fallido. La implementación en términos del uso de DaemonSets vs ReplicaSets es diferente entre los clústeres de Supervisor y TKG, pero la disponibilidad de los pods del sistema individuales es similar
Como se mencionó anteriormente, los clústeres de supervisor y TKG se implementan como un conjunto de tres controladores. En el caso de los clústeres de TKG, los desarrolladores pueden elegir una implementación de un solo controlador si los recursos están limitados. El acceso a kube-api se dirige a una IP virtual de Load Balancer y se distribuye entre los puntos finales de API disponibles. La pérdida de un nodo del plano de control no afecta la disponibilidad del clúster. Los balanceadores de carga basados en NSX se ejecutan en nodos perimetrales que se pueden implementar en una configuración activa / activa, lo que garantiza la disponibilidad de la IP virtual que los desarrolladores usarán para acceder a los clústeres.
Los clientes tienen la opción de habilitar VMware vSAN para proporcionar almacenamiento compartido de alta disponibilidad para los clústeres de Supervisor y TKG. vSAN combina el almacenamiento que es local para los hosts en una matriz de almacenamiento virtual que se puede configurar con las necesidades de redundancia del entorno. Los niveles de RAID se implementan en todos los hosts y brindan disponibilidad en los casos en que fallan los hosts individuales. vSAN es nativo del hipervisor ESXi y, por lo tanto, no se ejecuta como un conjunto de dispositivos de almacenamiento que podrían competir con las VM del clúster de Kubernetes por los recursos.
Los clientes que necesitan el aislamiento de una máquina virtual desde una perspectiva de seguridad y rendimiento, mientras desean orquestar la carga de trabajo a través de Kubernetes, pueden elegir vSphere Pods. Los operadores del sistema y de terceros también se pueden implementar como pods de vSphere. Se ejecutan en una máquina virtual en tiempo de ejecución de contenedor directamente en hosts ESXi y se comportan como cualquier otro pod. La disponibilidad se administra a través de objetos estándar de Kubernetes y sigue el patrón de Kubernetes para manejar fallas de pod. Cree una implementación con varias réplicas definidas y el controlador observará los pods fallidos y los volverá a crear. Las fallas de host harían que los vSphere Pods se volvieran a crear en nuevos hosts. Este patrón no usa vSphere HA, sino que aprovecha los controladores de Kubernetes para manejar fallas.
Analizamos la capacidad central dentro de la plataforma y ahora definiremos un conjunto de escenarios de falla dentro de una implementación de vSphere con Tanzu, luego analizaremos los enfoques para aumentar la disponibilidad en cada escenario.
Cuando un controlador o un nodo trabajador deja de estar disponible, los pods del sistema se volverán a crear en uno de los otros nodos disponibles. Los procesos fallidos de Linux son monitoreados y reiniciados por el sistema de inicio systemd. Esto es cierto tanto para el plano de control de TKG como para los nodos de trabajo, así como para el plano de control del supervisor. Los nodos Supervisor Worker son hosts ESXi reales, no ejecutan systemd y manejan las fallas del proceso de manera diferente. Las máquinas virtuales que se apagan se reinician automáticamente. El plano de control se implementa como un conjunto de 3 controladores, con una IP virtual de Load Balancer como el punto final de Kube-API para garantizar que durante el tiempo necesario para remediar la interrupción, el clúster todavía esté disponible. La corrección de los nodos de trabajo de TKG se maneja mediante el uso integrado de la capacidad MachineHeatlhCheck en ClusterAPI V1Alpha3.
La falta de disponibilidad de un host ESXi puede deberse a un breve reinicio o podría estar relacionada con una falla real del hardware. Al reiniciar, todas las VM del controlador y del nodo se reinician automáticamente en el host. Si el reinicio tarda más que el umbral de tiempo de espera de latido de HA, las VM se programan para su ubicación en otros hosts disponibles y se encienden. Las reglas de antiafinidad se mantendrán si los recursos lo permiten. En cualquier caso, los clústeres todavía están disponibles porque tienen varios nodos de controlador ubicados en hosts ESXi separados y se accede a ellos a través de un equilibrador de carga y pueden sobrevivir a la pérdida de un controlador.
Los hosts están organizados en racks físicos en el centro de datos. Los hosts en un rack se conectan a través de un conmutador Top of Rack y además se conectan a conmutadores de agregación adicionales. La pérdida de un conmutador, matriz de almacenamiento o alimentación podría hacer que un rack completo no esté disponible. La disponibilidad de un supervisor o clúster TKG depende de cómo se alinean los hosts con los racks. Algunos clientes colocarán todos los hosts en un clúster de vSphere en el mismo rack, lo que esencialmente hará que ese rack físico sea una zona de disponibilidad (AZ). La falla del bastidor haría que el Supervisor Cluster y todos los clústeres TKG no estuvieran disponibles. Otra opción es crear clústeres de vSphere a partir de hosts que residen en varios racks. Esta configuración garantiza que una sola falla de bastidor no haga que todos los hosts de vSphere Cluster no estén disponibles y aumenta la probabilidad de que el plano de control permanezca disponible.
Actualmente, el Programador de recursos distribuidos (DRS) no reconoce el bastidor. Esto significa que las reglas de antiafinidad para las máquinas virtuales del plano de control garantizarían la separación de hosts, pero no necesariamente garantizarían que los hosts estuvieran en racks separados. Se está trabajando para proporcionar una programación basada en rack que mejoraría esta disponibilidad.
Los clústeres de supervisor y TKG requieren almacenamiento compartido para permitir que los volúmenes persistentes sean accesibles a los pods que se pueden colocar en cualquier nodo, que podría residir en cualquier host. Tanto vSAN como los arreglos de almacenamiento tradicionales admiten varias configuraciones RAID que garantizan la disponibilidad de datos en caso de corrupción de discos individuales. vSAN agrega almacenamiento local adjunto a hosts físicos y también puede permanecer disponible si se produce una falla de host o incluso potencialmente de un rack.
Los clústeres extensibles de vSAN también brindarán la capacidad de dividir un único clúster de vSphere en dominios de fallas específicos de almacenamiento separados. Esto permitiría la disponibilidad de datos incluso con la pérdida de todo el dominio. Con hosts físicos distribuidos en varios racks, los volúmenes persistentes permanecerían disponibles durante las fallas tanto del host como del rack.
La redundancia física está integrada en la mayoría de los entornos de red de producción que brindan disponibilidad a través de fallas de hardware físico. Cuando se implementan con NSX-T, los clústeres Supervisor y TKG se ejecutan en redes superpuestas que son compatibles con la red física subyacente. Las VM de NSX Edge contienen los Vips de Load Balancer y enrutan el tráfico a los nodos del plano de control del clúster. NSX Edges se puede implementar en una configuración activa / activa que mantendría la red disponible en el caso de una falla del host o de la máquina virtual que afectó a un solo NSX Edge.
La disponibilidad de vCenter Server es fundamental para el funcionamiento completamente funcional de los clústeres de Supervisor y TKG. En el caso de una falla de vCenter, todas las máquinas virtuales, tanto el controlador como los nodos, continuarán ejecutándose y serán accesibles aunque con funcionalidad degradada. Los módulos de aplicaciones seguirían ejecutándose, pero la implementación y la gestión del sistema serían limitadas. La autenticación requiere que el servicio de inicio de sesión único devuelva un token de autenticación al archivo de configuración de kubectl. Solo los usuarios que tengan un token no vencido podrán acceder al sistema. Objetos como Load Balancers y PersistentVolumeClaims requieren interacción con vCenter y no se pueden administrar durante el ciclo de vida.
vCenter se puede proteger con vCenter High Availability. vCenter High Availability (vCenter HA) protege no solo contra fallas de hardware y host, sino también contra vCenter Server fallas de aplicaciones de . Al utilizar la conmutación por error automatizada de activo a pasivo, vCenter HA admite alta disponibilidad con un tiempo de inactividad mínimo. Esto aumentaría drásticamente la disponibilidad de los grupos Supervisor y TKG.
Hay un trabajo extenso en proceso para desacoplar los servicios principales de vCenter Server y llevarlos al nivel del clúster. El objetivo es proporcionar siempre una infraestructura que continúe funcionando incluso cuando vCenter tiene una interrupción
Ventajas y Características Entonces que va a pasar si tengo la oferta de vSphere+ ???? Voy a poder tener en el OnPrem (DC & Sitios Remotos) todos los vCenters que necesite sin tener que licenciarlos. vSphere+ añade valor a la infraestructura virtual existente, local y de varias maneras: Paso 1 – Crear una cuenta y…
La semana pasada en el Veeam User Group de MCA LaTAM en Telegram, donde charlamos de problemas que pueden ir teniendo, o consultas varias. (Dejo por aqui el link para que unan a este grupo por Telegram) Unirse al Veeam User Group en Telegram Aqui Uno de los usuarios pregunto si existía alguna tool donde…
Requisitos del dispositivo 📱 🐧💻 Linux Puede inscribir dispositivos que ejecuten cualquier distribución de Linux que se ejecute en arquitecturas x86_64, ARM5 o ARM7 en Workspace ONE UEM. Los instaladores se crean para distribuciones y arquitecturas específicas. Asegúrese de que está utilizando el instalador correcto para su caso de uso. El dispositivo debe estar ejecutando…

La comunidad de código abierto está convergiendo en Prometheus como la solución preferida para abordar los desafíos asociados con el monitoreo de Kubernetes. Fue desarrollado previamente por SoundCloud y luego donado al CNCF. Prometheus admite aplicaciones de instrumentos en muchos idiomas. Ofrece una integración de Kubernetes incorporada y es capaz de descubrir recursos de Kubernetes como nodos, servicios y pods y capturar métricas de ellos.
Prometheus tiene un navegador de expresiones, que se utiliza principalmente para depurar. Para tener cuadros de mando atractivos, usaremos Grafana: una popular plataforma abierta para visualización y análisis. Grafana tiene una fuente de datos integrada para realizar consultas en Prometheus.
1. Instale Prometheus con Helm CLI
Para implementar Prometheus, aprovecharemos el proyecto del operador prometheus. Prometheus Operator proporciona implementación y administración nativas de Kubernetes de Prometheus y los componentes de monitoreo relacionados. Este proyecto tiene como objetivo simplificar y automatizar la configuración de una pila de monitoreo basada en prometheus para clústeres de Kubernetes
helm search repo prometheus-operator
helm install prometheus-operator bitnami/prometheus-operator \
-n monitoring \
--version 0.21.3 \
--set useHelm3=true --set prometheus.service.type=LoadBalancer \
--set prometheus.persistence.enabled=true
2. Accede a la interfaz de usuario de Prometheus
Prometheus viene con una interfaz de usuario web simple. Nos permite ver gráficos simples, la configuración y las reglas de Prometheus, y el estado de los puntos finales de monitoreo.

3. Instale Grafana con Kubeapps
Para instalar Grafana, usaré la aplicación Kubeapps (Bitnami Project) que tengo ejecutándose en mi Cluster TKG

4. Trabajar con Grafana

4.1 Ahora que tenemos Grafana instalado, agreguemos fuentes de datos.

1. En la siguiente pantalla, asegúrese de estar en la pestaña Fuentes de datos y haga clic en el botón Agregar fuente de datos

Grafana incluye soporte integrado para Prometheus.



Aquí voy a importar un Dashboard desde Grafana

Cada panel de Grafana.com tiene una identificación única. Importemos el panel de detalles de clúster K8 de xmurias, que tiene un ID de 10856.


También Puede buscar e importar dashboards de Kubernetes desde https://grafana.com/grafana/dashboards

Espero que hayas disfrutado esta entrada de Blog y puedas probarlo!!!

Nyansa para extender VMware SD-WAN por VeloCloud Visibilidad, análisis y resolución de problemas en la LAN
Por Sanjay Uppal, vicepresidente y gerente general de VeloCloud Business Unit, VMware
En enero de 2019, VMware anunció la visión para la evolución y el SD-WAN, la llamaron «Network Edge«, basándose en la creencia de que SD-WAN tiene un potencial ilimitado para apoyar los avances tecnológicos en el mundo de las redes. Parte de esa visión fue la expansión de SD-WAN más allá de la red de área amplia (WAN) y dentro de la red de área local (LAN) para brindar una comprensión aún más profunda de extremo a extremo de cómo se está utilizando y entregando toda la red y la promesa de self-healing networks.
Al adquirir Nyansa, Inc. (pronunciado «knee-ans-sah»). Combinando las capacidades líderes de la industria de VMware SD-WAN de VeloCloud con la oferta de la plataforma AIOps basada en la nube de Nyansa, los usuarios tendrán acceso a una plataforma única que puede entregar datos integrales y procesables sobre el tráfico de red y el rendimiento de las aplicaciones desde la nube, a las sucursales, al usuario final y a través de sus dispositivos con cable o inalámbricos.
Es una solución altamente diferenciada que cumple con un verdadero punto de dolor del cliente, y el equipo de Nyansa haya decidido unirse a VMware en este viaje de transformación de la red.
Más información:
📢 Atención #BlockChain#Fans 👀👇Hemos estado trabajando 👨🏭 duro desde #VMworld del año pasado donde Lanzamos 🚀 #VMware #Blockchain #VMBCAhora en el #VMworld2021 🌏Aprende 🤓 cómo #blockchain está transformando las #industrias 🏭 y ponete al día sobre las finanzas 💰 descentralizadas #DeFi, los #NFT y los intercambios descentralizados #DEX 💳 con estas sesiones: 📌 Sesión VI1553: Obtén una comprensión más profunda de #DeFi 💰 y cómo funciona un #DEX 💳 . Nos sumergiremos en los detalles técnicos…
Visión general Las ofertas verificadas de VMware Cloud existen de varias formas. Este artículo https://www.veeam.com/kb4207 destaca consideraciones específicas cuando se trabaja con Veeam Disaster Recovery Orchestrator, Veeam Backup & Replication y Veeam ONE con fines de orquestación de recuperación ante desastres. Dependiendo de la solución VMware específica del proveedor que ofrece algunas características y permisos,…
Les cuento un poco de mi, Soy Esteban Prieto vivo en Argentina – Buenos Aires, actualmente trabajo como System Engineer en VMware, soy Veeam Vanguard 2019/21 Class 💯 y Veeam Legend First Class 2021 👨🎓. Lo primero que descubrí siendo parte de las 2 comunidades mas importantes de tecnología, es que el éxito de cada…
CDP – Retention Policies Una política de retención define durante cuánto tiempo Veeam Backup & Replication debe almacenar los puntos de restauración para las réplicas de VM. Veeam Backup & Replication ofrece dos esquemas de políticas de retención: Retención a largo plazo Retención a corto plazo Retención a largo plazo Veeam Backup & Replication conserva…
Se ha producido un error. Actualiza la página y/o inténtalo de nuevo.

Habilitación de la continuidad del negocio con VMware SD-WAN

VMware SD-WAN ™ de VeloCloud® potencia rápidamente una fuerza de trabajo digital remota y permite la continuidad del negocio, ahora y en el futuro, al ofrecer simplicidad al consumidor, calidad del negocio y escalabilidad en la nube. Con VMware SD-WAN, las organizaciones pueden admitir un acceso seguro y confiable para aplicaciones tradicionales y SaaS, incluidas VOIP, UCaaS, Collaboration y VDI, de proveedores como Microsoft 365, Zoom Meeting, Vonage, Ring Central, Windstream, VMware Horizon Cloud, y más. Disponible como servicio respaldado por más de 120 proveedores de servicios en todo el mundo, VMware SD-WAN ofrece una experiencia de teletrabajo óptima para el trabajo empresarial en usuarios domésticos a través de un modelo de hiperescala con una red global de más de 2,000 puertas de enlace en la nube en más de 100 PoP.
Los beneficios de SD-WAN incluyen:


Nuestro aprovisionamiento Zero Touch (ZTP) ofrece aprovisionamiento y configuración simplificados sin la necesidad de un administrador de red o experto. VMware SD-WAN ofrece operaciones simplificadas de día 2 para la resolución de problemas y la gestión a través de la automatización y la gestión basada en políticas

Espero que les haya gustado mi entrada, les recomiendo que visiten la pagina de Velocloud, hay muchísima información de SDWAN de VMware, quizás puede ser la solución para tu empresa.
Saludos!!!
Saludos !! Cuando se enfrentan a eventos impredecibles como por ejemplo brotes de salud pública, se les pide a las organizaciones que tomen medidas y permitan que su fuerza laboral acceda a los recursos corporativos de forma remota. En muchos casos, el usuario tiene una máquina física con Windows ubicada en su lugar de trabajo normal, la oficina. Esa máquina tiene todas las aplicaciones, acceso a datos y herramientas que el usuario necesita para hacer su trabajo. El desafío es que el usuario no puede acceder físicamente a su máquina.
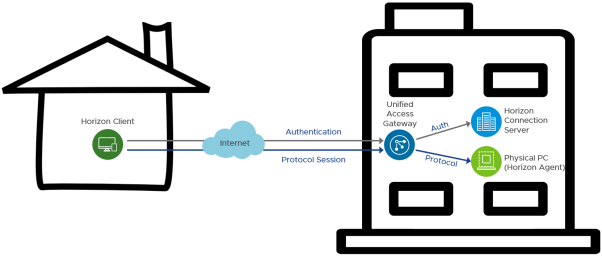
Horizon también ofrece la opción de intermediar el acceso a máquinas físicas. Esto proporciona una experiencia excelente y familiar para los empleados.
La intermediación a máquinas físicas se puede implementar con un entorno Horizon 7 existente o con uno nuevo. Con componentes mínimos requeridos, esta solución se puede implementar rápidamente.
Horizon 7 permite el acceso a máquinas físicas basadas en la oficina mediante el uso de unos pocos componentes principales de Horizon:
| Nota: Horizon Client está disponible para todas las plataformas principales del sistema operativo, incluidos Windows, Mac, Linux, iOS, Android, Chrome OS y también como acceso HTML |


Un único servidor de conexión admite un máximo de 4.000 sesiones, aunque se recomiendan 2.000 como práctica recomendada. Para garantizar que el entorno incluya redundancia y pueda manejar fallas, implemente un servidor más del requerido para la cantidad de conexiones ( n +1)
Unified Access Gateway ofrece tres opciones de tamaño durante la implementación: estándar, grande y extra grande. Al implementar para proporcionar servicios de borde seguros para Horizon, se debe usar el tamaño estándar.
Un Unified Access Gateway de tamaño estándar admite 2.000 sesiones de Horizon
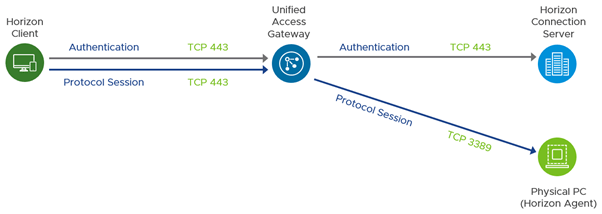
Para garantizar una comunicación correcta entre los componentes, es importante comprender los requisitos del puerto de red para la conectividad en una implementación de Horizon 7. El siguiente diagrama muestra los puertos necesarios para permitir una conexión Blast Extreme.

Los puertos de red que se muestran son puertos de destino. Las siguientes tablas muestran más detalles e indican el origen, el destino y la dirección de inicio del tráfico. Los protocolos Horizon UDP son bidireccionales. Los firewalls con estado deben configurarse para aceptar datagramas de respuesta UDP.
El siguiente diagrama muestra los puertos necesarios para permitir una conexión RDP.
Esta sección proporciona una descripción general del proceso de implementación de Horizon 7. Esto supone que aún no tiene un entorno Horizon 7 en su lugar. Si existe un entorno de Horizon 7 existente, es posible que pueda usarlo en lugar de configurar un entorno separado.
A un alto nivel, los pasos involucrados son:
Antes de implementar y configurar la solución, tenga en cuenta lo siguiente y ajuste la configuración de la solución en consecuencia.
Evalúe las políticas de energía para las máquinas físicas y realice cambios para minimizar la posibilidad de que las máquinas físicas se apaguen.
Comprenda cómo los usuarios usan normalmente sus escritorios, qué tipo de grupo de escritorios es el más adecuado y cómo se les debe asignar acceso a los usuarios.
Un usuario por PC física
PC físicas agrupadas
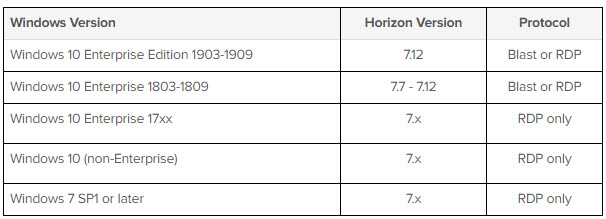
Si usa el protocolo RDP, asegúrese de que la autenticación de nivel de red (NLA) esté deshabilitada en Windows. Consulte los artículos de la base de conocimientos de VMware. La conexión de escritorio remoto con NLA no es compatible con Horizon View (67832) y la conexión a los escritorios View usando el protocolo RDP falla con el código de error 2825 (1034158) para obtener más detalles
Horizon Client para Mac no admite el uso del protocolo de visualización RDP. Si los dispositivos Mac se usan como clientes, verifique que la combinación de la versión de Windows en la PC física y la versión de Horizon 7 admitan el uso de Blast
Horizon 7 requiere una infraestructura de Microsoft Active Directory para la autenticación y administración de usuarios. Los niveles funcionales de dominio de los Servicios de dominio de Active Directory (AD DS) compatibles son:
El software Horizon Connection Server debe instalarse en los servidores de Microsoft Windows. Deben ser servidores dedicados sin ningún otro software empresarial instalado. Windows Server 2019, 2016 o 2012 R2 es compatible.
Se recomienda que a estos servidores de Windows se les asigne al menos 4 vCPU y al menos 10 GB de RAM
Instalación
Esta guía no pretende reemplazar la documentación de Horizon 7 . Siga las secciones relevantes de la documentación de instalación de Horizon 7 para instalar los siguientes componentes en el siguiente orden:
Configuración posterior a la instalación
Conéctese al primer servidor de conexión y realice las siguientes tareas en el siguiente orden:
Cuando instala por primera vez un servidor de conexión, utiliza certificados autofirmados. VMware no recomienda que los use en producción. En un nivel alto, los pasos para reemplazar los certificados en los servidores de conexión son:
Unified Access Gateways
Unified Access Gateway es un dispositivo Linux reforzado que está disponible como un archivo OVF (formato de virtualización abierto) descargable. Al implementar para proporcionar servicios de borde seguros para Horizon, se debe usar el tamaño estándar. Esto asigna 2 vCPU y 4 GB de RAM al dispositivo
Certificados
Los certificados TLS / SSL se utilizan para asegurar las comunicaciones para el usuario entre Horizon Client y Unified Access Gateway y entre Unified Access Gateway y los recursos internos
Instalación de Horizon Agent
Debe instalar Horizon Agent en las máquinas físicas para registrarlos con los Servidores de conexión, de modo que luego pueda agregarlos de un grupo de escritorio manual.
Script de automatización
Para automatizar la instalación silenciosa y más, se ha desarrollado un script de PowerShell que implementa de forma remota y silenciosa el agente Horizon. Esto se puede descargar en https://github.com/andyjmorgan/HorizonRemotePCHelperScripts
Pool de escritorio
Se debe crear un grupo de escritorios manual para contener las máquinas físicas registradas que han instalado Horizon Agent.
Al definir el grupo de escritorios, use la siguiente configuración:

Una vez que se crea el grupo, se requieren tres pasos para agregar y preparar una máquina física para que el usuario se conecte.
Cliente Horizon
Idealmente, los usuarios deben instalar Horizon Client en la computadora de su casa o dispositivo personal.

El cliente se puede descargar de varias maneras. Los clientes se pueden descargar de VMware, en https://www.vmware.com/go/viewclients . Si el dispositivo de punto final es Android o iOS, Horizon Client también se puede encontrar en Google Play Store y Apple App Store.
Espero Hayan disfrutado de este Post !!
